优化 Flux 性能
目录
优化 Flux 性能
您正在使用 InfluxDB Cloud,并充分利用 Flux 来创建自定义数据处理任务、检查和通知。然而,您注意到一些 Flux 脚本的执行速度不如预期。在本节中,我们将学习优化 Flux 性能的最佳实践和工具。
Flux 性能优化的一般建议
在深入研究可用于优化 Flux 性能的一些工具之前,让我们先深入了解一些关于 Flux 性能优化的一般建议。
- 利用下推模式。
- Schema 变更函数应该在查询的最后应用。
- 使用变量以避免多次查询数据。
- 根据需要将处理工作划分到多个任务中。
我们将在以下章节中详细讨论每个建议。
利用下推模式
为了提供优化指南的上下文,让我们先花点时间了解 Flux 的工作原理。Flux 能够高效地查询数据,因为某些函数将数据转换工作负载下推到存储,而不是在内存中执行转换。执行此工作的函数组合称为下推模式。为了优化 Flux 查询,最好尽可能尝试使用下推模式。要了解更多关于下推模式和 Flux 如何工作的信息,请阅读 Flux 中级用户面临的五大障碍和优化 Flux 的资源 中的“解决方案 2:了解内存优化和新的下推模式以优化您的 Flux 脚本”。
正确使用 Schema 变更函数
Schema 变更函数是指任何更改 Flux 表中列的函数。它们包括 keep()、drop()、rename()、duplicate() 和 set() 等函数。如果您的查询中使用了 聚合 或 选择器 函数,请尝试在应用聚合函数之后包含 Schema 变更函数,以保留您可能拥有的任何下推模式。此外,尽可能尝试用组键的更改替换 keep() 或 drop()。例如,当在两个桶的两个字段上执行 join() 时,请在所有类似列上进行连接,而不是事后删除列。我们使用 array.from() 函数生成此示例的数据。
import "array"
import "experimental"
start = experimental.subDuration(
d: -10m,
from: now(),
)
bucket1 = array.from(rows: [{_start: start, _stop: now(), _time: now(),_measurement: "mymeas", _field: "myfield", _value: "foo1"}])
|> yield(name: "bucket1")
bucket2 = array.from(rows: [{_start: start, _stop: now(), _time: now(),_measurement: "mymeas", _field: "myfield", _value: "foo2"}])
|> yield(name: "bucket2")
我们查询的 带注释的 CSV 输出如下所示
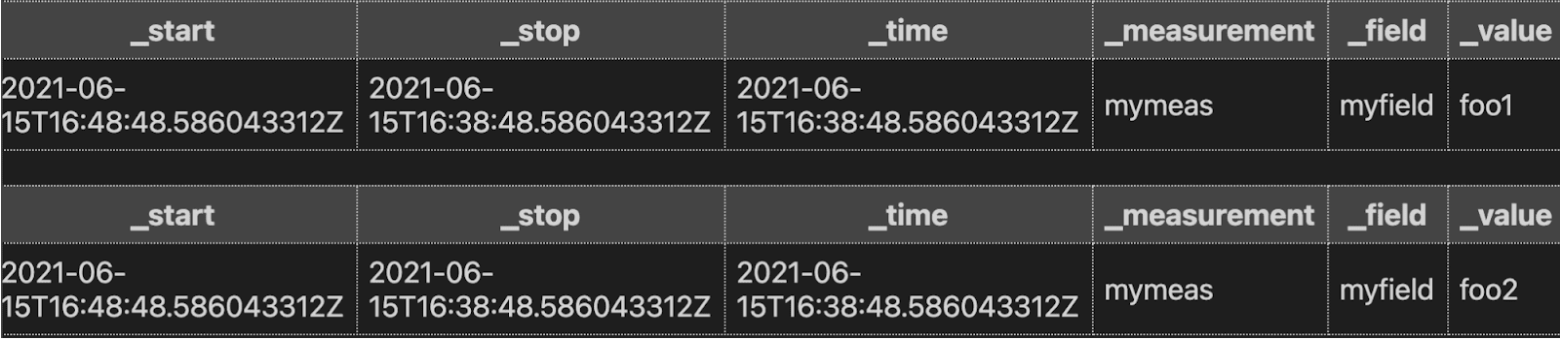
**不要**在 join() 之后不必要地使用 drop()
join(tables: {bucket1: bucket1, bucket2: bucket2}, on: ["_time"], method: "inner")
|> drop(columns:["_start_field1", "_stop_field1", "_measurement_field1", "myfield1"])
|> yield(name: "bad_join")
**要**通过连接类似列来替换组键的更改
join(tables: {bucket1: bucket1, bucket2: bucket2}, on: ["_start","_stop""_time", "_measurement","_field"], method: "inner")
|> yield(name: "good_join")
产生相同的结果

使用变量避免多次查询数据
将结果存储在变量中并引用它,而不是多次查询数据。换句话说
**不要**这样做
from(bucket: "my-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "my_measurement")
|> mean()
|> set(key: "agg_type",value: "mean_temp")
|> to(bucket: "downsampled", org: "my-org", tagColumns:["agg_type"])
from(bucket: "my-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "my_measurement")
|> count()
|> set(key: "agg_type",value: "count_temp")
|> to(bucket: "downsampled", org: "my-org", tagColumns: ["agg_type"])
**要**这样做
data = from(bucket: "my-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "my_measurement")
data
|> mean()
|> set(key: "agg_type",value: "mean_temp")
|> to(bucket: "downsampled", org: "my-org", tagColumns: ["agg_type"])
data
|> count()
|> set(key: "agg_type",value: "count_temp")
|> to(bucket: "downsampled", org: "my-org", tagColumns: ["agg_type"])
将处理工作划分到多个任务中
您是否尝试在同一个任务中执行 Schema 变更、透视、连接、复杂数学运算和映射?如果是,并且您遇到了较长的执行时间,请考虑将部分工作划分到多个任务中。分离处理工作并并行执行这些任务可以帮助您减少总体执行时间。
Flux Profiler 包
Flux Profiler 包 根据您的查询提供性能信息。根据文档,以下 Flux 查询
import "profiler"
option profiler.enabledProfilers = ["query", "operator"]
from(bucket: "noaa")
|> range(start: 2019-08-17T00:00:00Z, stop: 2019-08-17T00:30:00Z)
|> filter(fn: (r) =>
r._measurement == "h2o_feet" and
r._field == "water_level" and
r.location == "coyote_creek"
)
|> map(fn: (r) => ({ r with
_value: r._value * 12.0,
_measurement: "h2o_inches"
}))
|> drop(columns: ["_start", "_stop"])
从 Profiler 生成以下表格
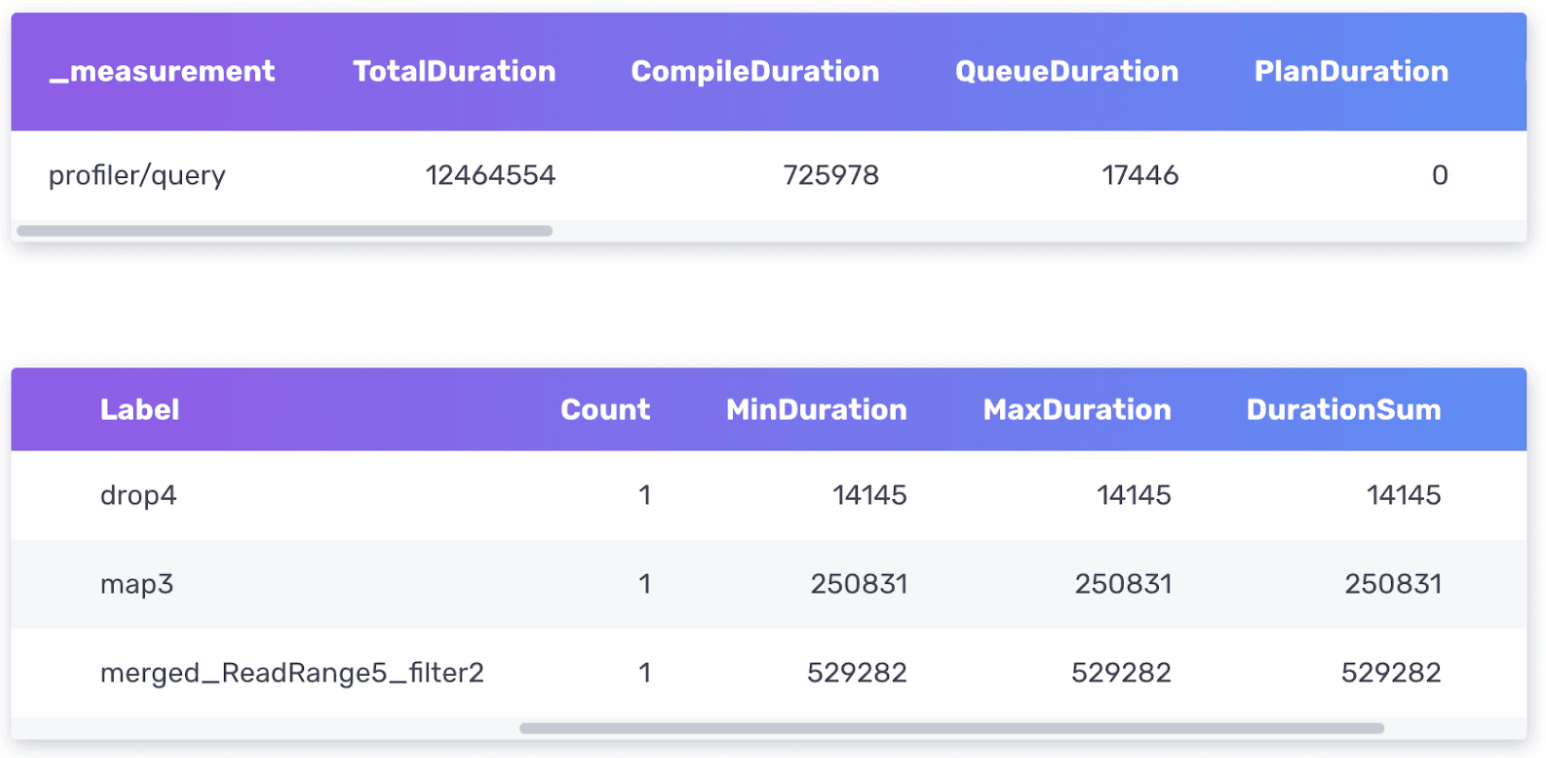
Flux Profiler 以纳秒为单位输出有关查询的性能信息。
- 第一个表格提供有关整个查询的信息,包括执行查询所花费的总持续时间以及编译、排队等所花费的时间。
- 第二个表格提供有关查询在哪里花费最多时间的信息。
需要注意的两个最重要的列是第一个表格中的 TotalDuration 列和第二个表格中的 DurationSum 列。此查询执行速度非常快,因此我不必担心对其进行优化。但是,我将描述进一步优化它的思路。
首先,我会尝试确定查询的哪一部分执行时间最长。从上面的查询中,我们可以看到 merged_ReadRange5_filter 操作的 DurationSum 最大,为 529282 ns。如果我计划将此查询转换为任务并按计划执行此转换工作,我应该首先考虑的是缩短查询数据的时间范围并更频繁地运行任务。
接下来,我注意到 map() 函数贡献了第二长的 DurationSum 值。回顾我的 map() 函数,我不得不怀疑使用 map() 重命名测量值是否是最高效的方法。也许我应该尝试使用 set() 函数,如下所示
from(bucket: "noaa")
|> range(start: 2019-08-17T00:00:00Z, stop: 2019-08-17T00:30:00Z)
|> filter(fn: (r) =>
r._measurement == "h2o_feet" and
r._field == "water_level" and
r.location == "coyote_creek"
)
|> drop(columns: ["_start", "_stop"])
|> set(key: "_measurement",value: "h2o_inches")
|> map(fn: (r) => ({ r with
_value: r._value * 12.0,
}))
还要注意,我切换了函数的顺序,并在 map() 函数之前应用了 drop() 和 set() 函数。运行 Profiler 后,我看到 TotalDuration 时间减少了,这表明这些都是良好的更改。由于 Flux 会不断进行性能优化,并且每个人的 Schema 都非常不同,因此没有关于 Flux 性能优化的硬性规则。相反,我鼓励您利用 Profiler 并进行一些实验,以找到最适合您的解决方案。
使用 Visual Studio Code 的 Flux 扩展来简化 Flux 优化发现
如果您还没有尝试过,我鼓励您安装 Flux 扩展 以用于 Visual Studio Code。要使用 Flux 扩展查询您的 InfluxDB Cloud 帐户,您必须先对其进行配置并 连接到您的云帐户。我喜欢在尝试调试复杂的 Flux 脚本或尝试优化 Flux 脚本的性能时使用 Flux 扩展和 VS Code,因为我可以保存 Flux 脚本并同时比较 Profiler 的输出。
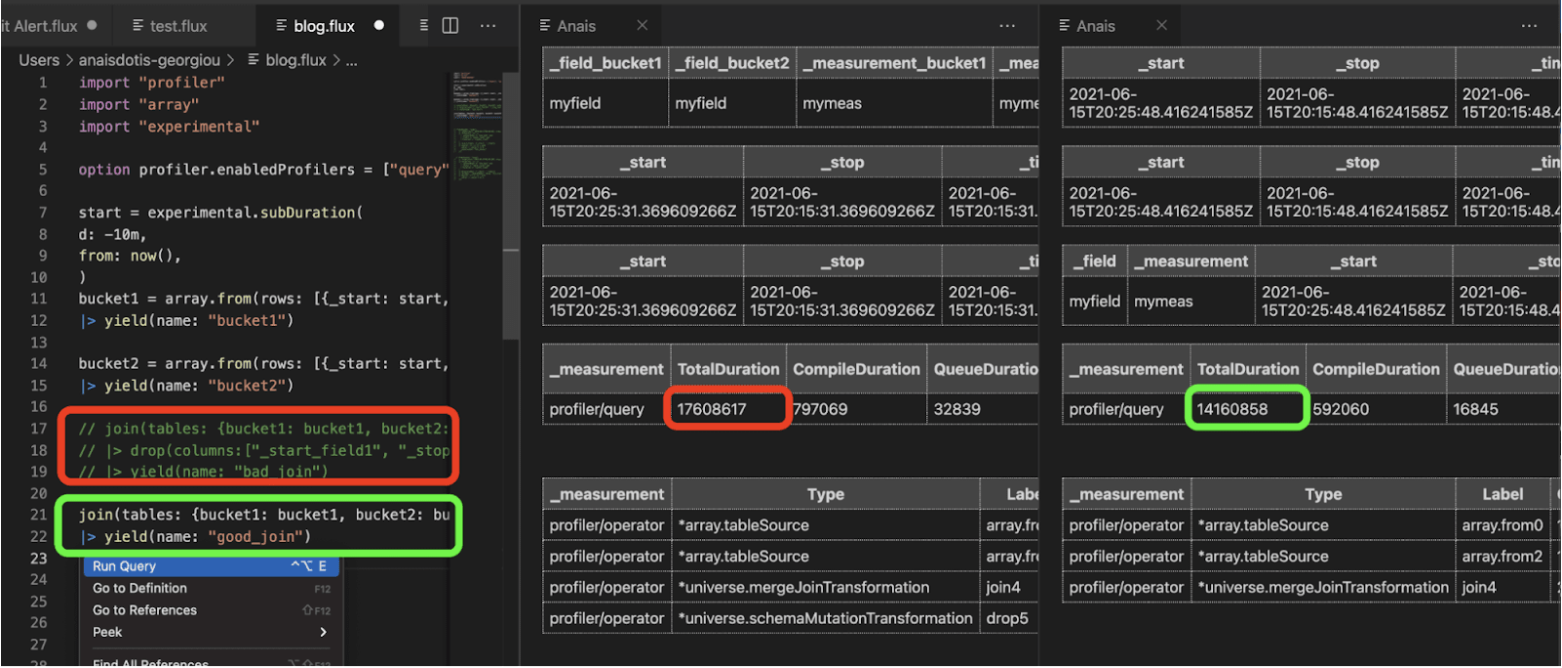
原始的“bad_join”查询(红色)被注释掉了,因为我先运行了它。它的 TotalDuration 时间为 17608617 ns。在多个类似列上连接并删除 drop() 将性能提高到 14160858 ns。
我决定测试上面“正确使用 Schema 变更函数”一节中描述的查询。Profiler 证实了我的假设:在多个类似列上连接比追溯删除冗余列更有效。虽然您也可以在 InfluxDB UI 中执行此工作,但我发现 Profiler 输出的并排比较对此类实验很有帮助。
其他技巧
以下是在尝试优化 Flux 查询性能时可以考虑的其他一些替换或想法:
- 您可以使用 experimental.join() 函数代替 join() 函数吗?
- 您可以在应用 map() 函数之前应用任何可以减少表中行数的组吗?
- 您可以将任何正则表达式调整得尽可能具体吗?
- 您可以使用 rows.map() 代替 map() 吗?
|> sort(columns: ["_time"], desc: false) |> limit(n:1)的性能是否优于|> last()?
获取帮助的最佳实践
当您在优化 Flux 脚本性能方面需要帮助时,无论是在社区论坛、Slack还是通过技术支持,请在您的帖子或请求中包含以下信息。
- 哪个查询出现了问题?
- 请务必分享该查询以及 Profiler 的输出结果。
- 您的数据的基数是多少?(有多少个序列)
- 尝试使用InfluxDB 运行监控模板来帮助您查找数据的基数。
- 或者,尝试使用 schema.cardinality() 函数来帮助您查找数据的基数。
- 您的数据的密度是多少?(每个序列每单位时间有多少个点)
- 尝试使用InfluxDB Cloud 使用情况模板来帮助您识别 InfluxDB Cloud 帐户中的数据。
- 有关数据结构(存在哪些测量、字段和标签键)的一般信息总是有帮助的。
- 尝试使用schema 包来分享您的数据结构。
- 您期望查询运行的速度有多快?这个期望的依据是什么?
在帖子中包含尽可能多的这些信息将有助于我们更好地、更快速地为您提供帮助。上述几点也适用于内存限制问题。