Telegraf
目录
Telegraf
Telegraf 是一个开源的、插件驱动的指标和事件采集代理。Telegraf 允许您:
- 采集数据。
- 解析、聚合、序列化或处理数据。
- 将数据写入各种数据存储。
与 InfluxDB 类似,它编译成单个二进制文件。Telegraf 代理和插件可通过单个 TOML 配置文件进行配置。Telegraf 也是数据库无关的。它还具有批处理、缓存、缓冲和抖动功能,以确保您的数据采集和写入成功。换句话说,如果您正在寻找一个工具来帮助您采集和写入数据,那么 Telegraf 值得一试。
Telegraf 插件有 7 种类型:
- 输入插件:这些插件从各种输入源获取数据。有超过 200 个输入插件可供选择。
- 输出插件:这些插件格式化输入数据并将其写入各种数据存储。
- 聚合器插件:这些插件发出数据的聚合。
- 解析器插件:这些插件帮助您将各种数据格式解析为行协议。
- 处理器插件:这些插件帮助您转换和过滤指标。
- 序列化器插件:这些插件将数据序列化为各种格式。
- 外部插件:这些插件是由社区贡献的插件,它们利用 Telegraf 的 execd 输入、输出 或 处理器 插件。execd 插件使 Telegraf 可以用任何语言进行扩展,以便您可以从任何来源采集数据、处理数据并将数据写入任何来源。
安装
要安装 Telegraf,请访问 Influxdata 的下载页面并选择平台类型。然后将命令复制并粘贴到您的命令行中。如果您使用的是 MacOS,则可以使用包管理器 Homebrew 通过以下命令安装 Telegraf:brew update
brew install telegraf
配置和运行
有两种配置 Telegraf 的方法:
- 通过 InfluxDB UI
- 通过命令行
通过 InfluxDB UI
InfluxDB UI 在引导新用户方面也表现出色,无论他们是 InfluxDB OSS 用户还是 InfluxDB Cloud 免费套餐 用户。InfluxDB UI 允许您轻松利用 Telegraf。您可以使用 InfluxDB UI 从数百个不同的 Telegraf 插件中进行选择,创建 Telegraf 配置,并帮助他们运行 Telegraf。您还可以使用 InfluxDB UI 将其他插件添加到现有的 Telegraf 配置中,这为用户提供了 Telegraf 提供的所有灵活性和功能。
要在 InfluxDB UI 中创建 Telegraf 配置,请导航到“**数据**”选项卡,然后在 Telegraf 插件列表下选择要添加的插件。或者,您也可以在“**数据**”选项卡顶部搜索要使用的插件。让我们使用 CPU 输入插件 从您的机器收集 CPU 指标。
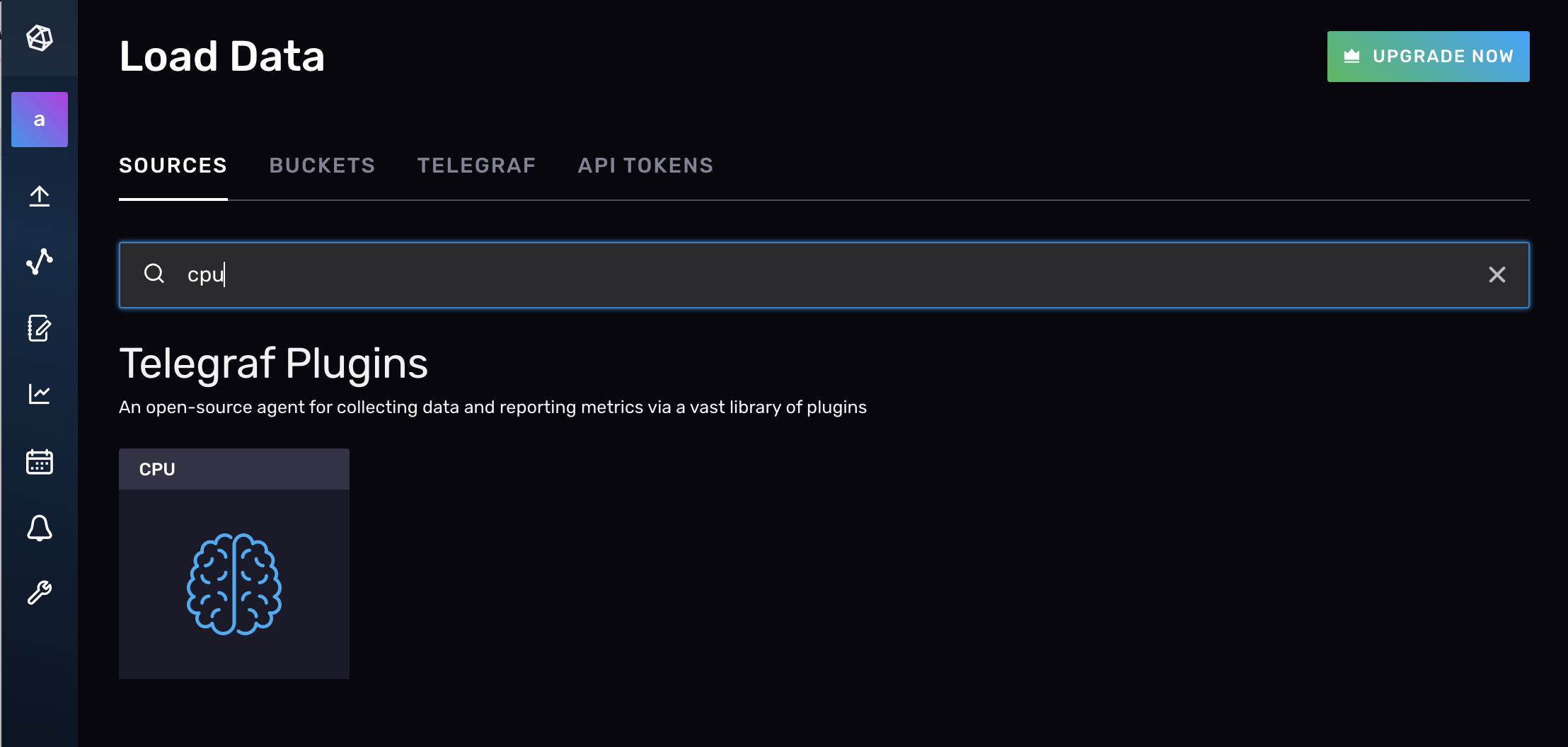
接下来,从下拉菜单中选择“**创建配置**”。
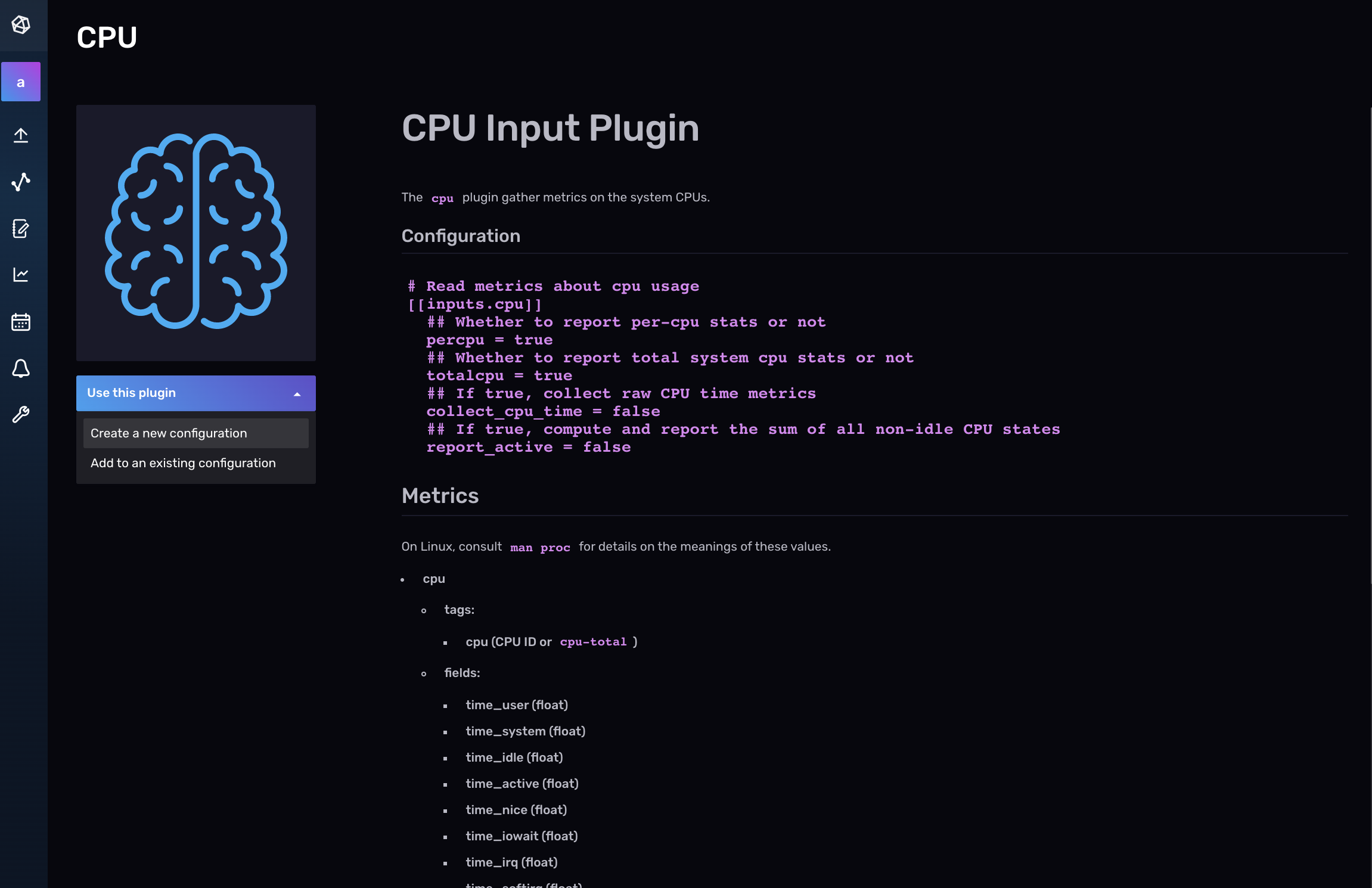
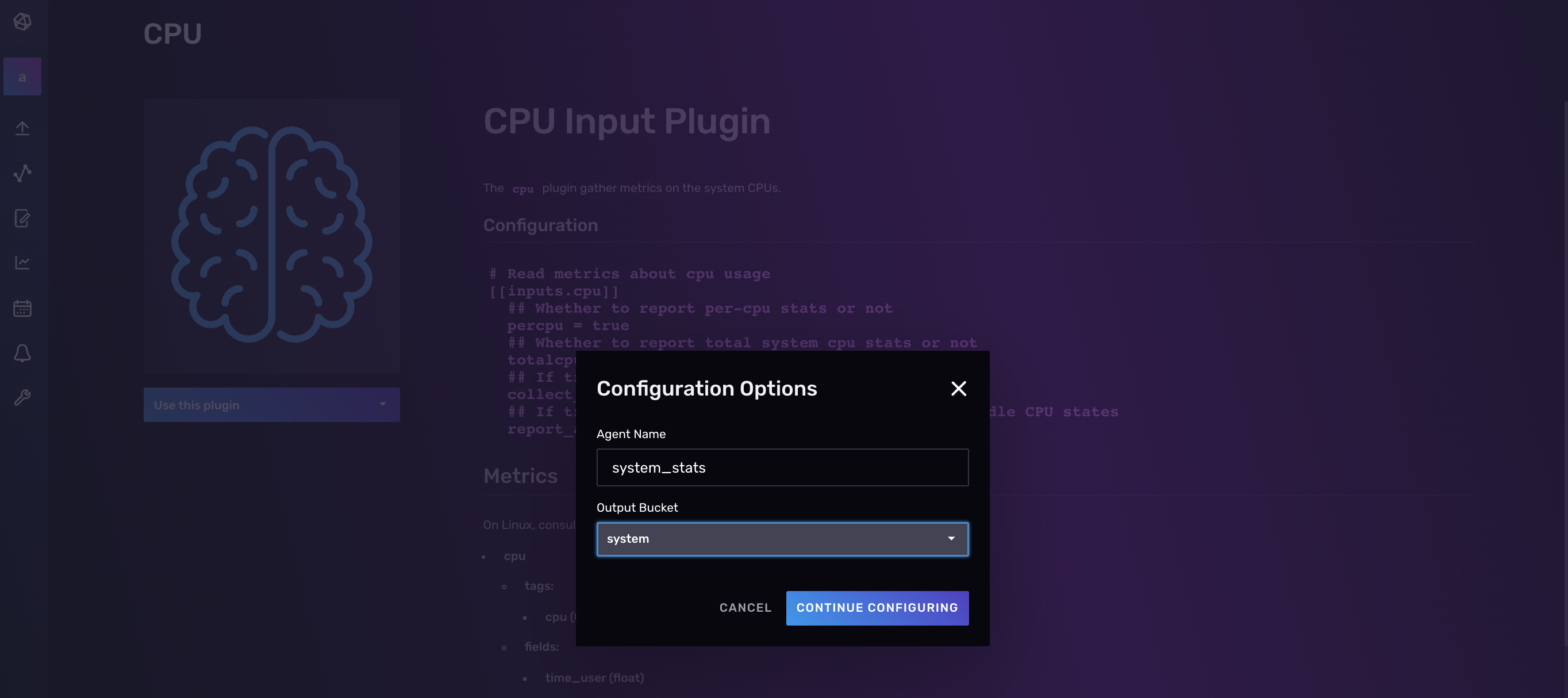
现在您可以命名您的 Telegraf 配置,并执行以下任一操作:
- 选择您希望 Telegraf 代理写入数据的桶。
- 创建一个新桶来写入数据。
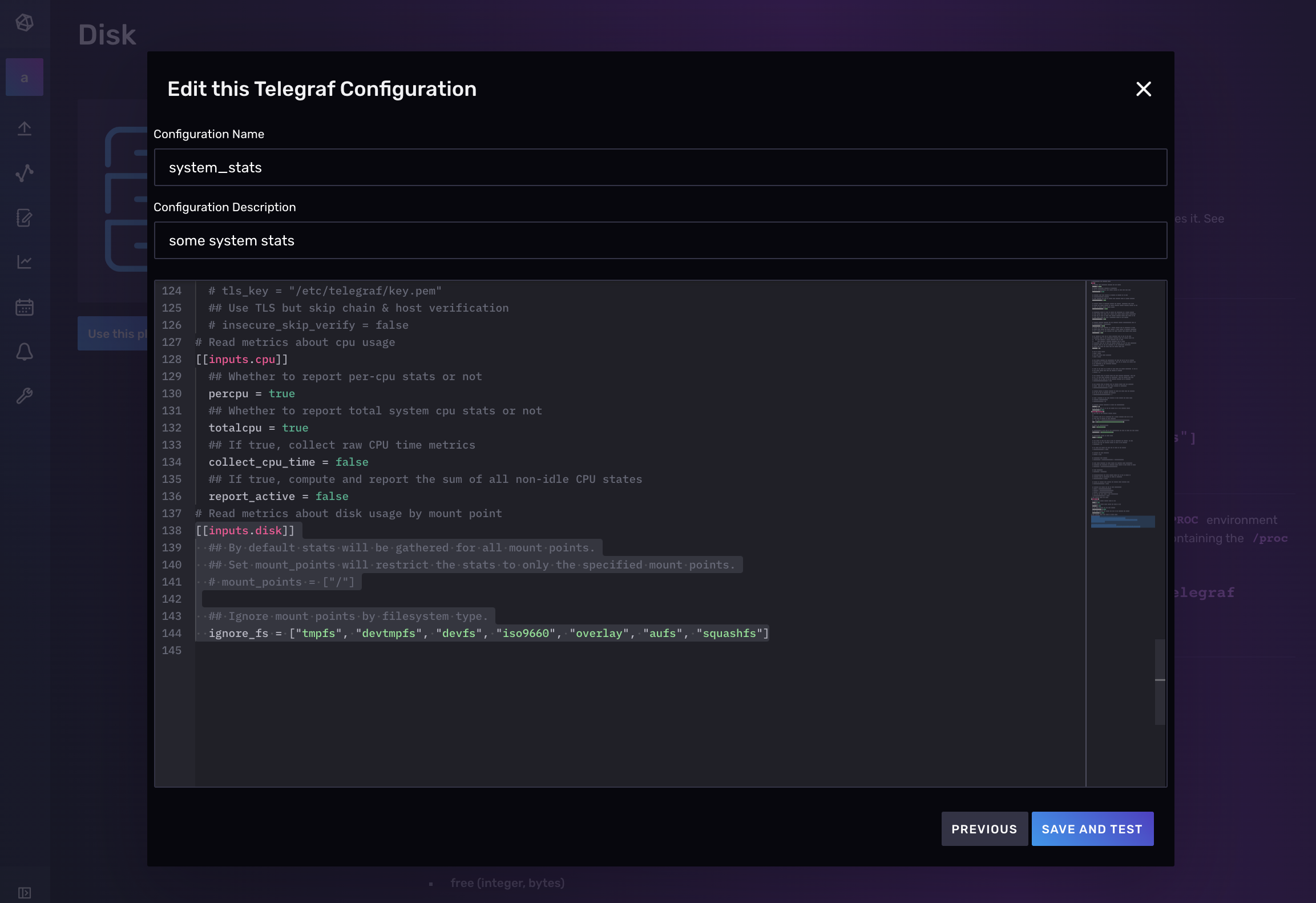
在下面的屏幕截图中,将您的配置命名为“system_stats”,并选择“system”作为输出桶。
选择“**继续配置**”继续下一步,您可以在其中添加 Telegraf 配置描述(可选)并编辑配置的任何部分。要了解有关如何配置单个插件的更多信息,请查找您的插件并访问 GitHub 以获取所选插件的文档。
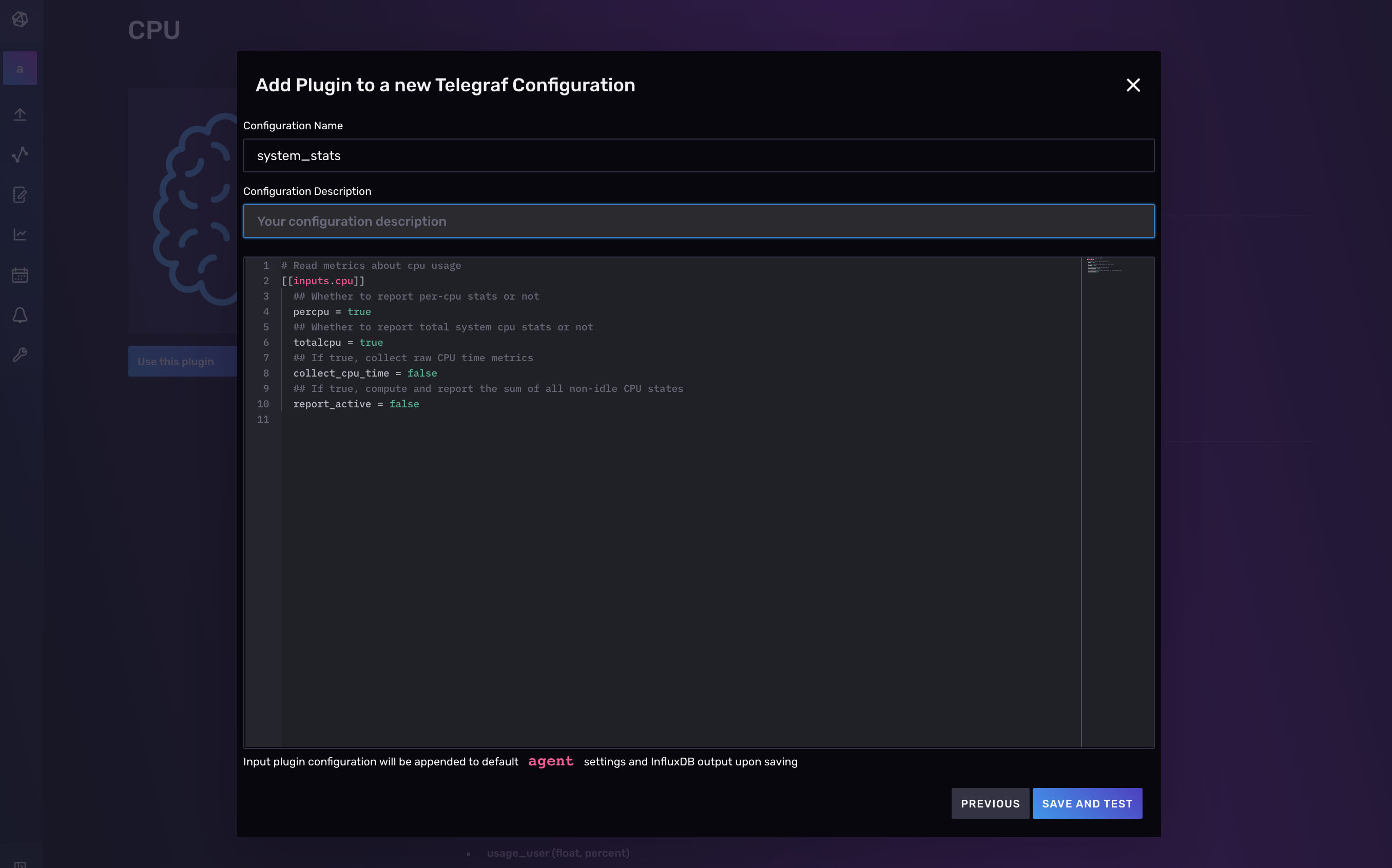
最后,单击“**保存并测试**”将您带到设置说明页面。按照说明进行操作:
- 安装 Telegraf(如果您尚未安装)
- 配置 API 令牌
- 启动 Telegraf
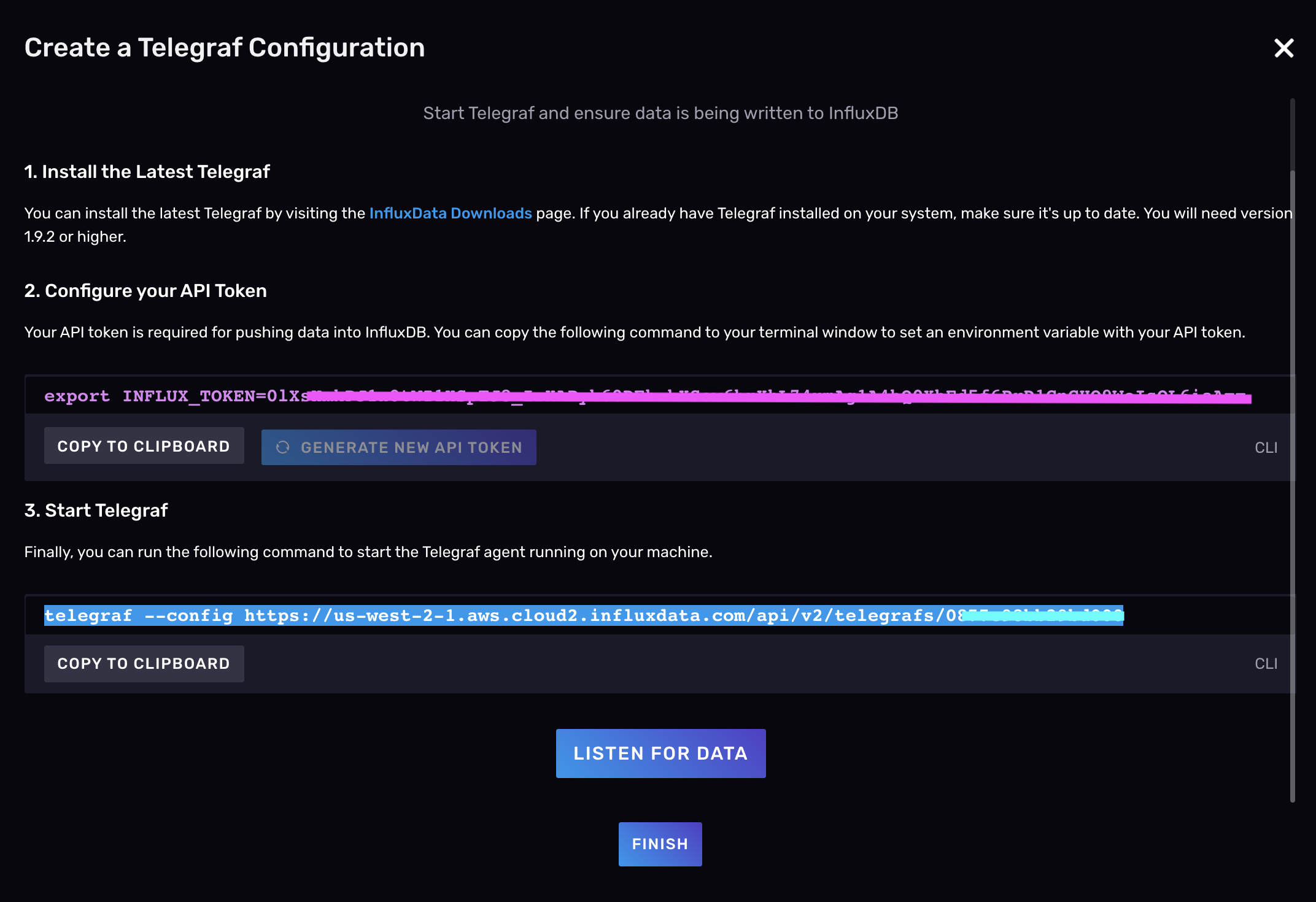
单击“**侦听数据**”按钮以验证您是否已使用 Telegraf 成功采集和写入数据。
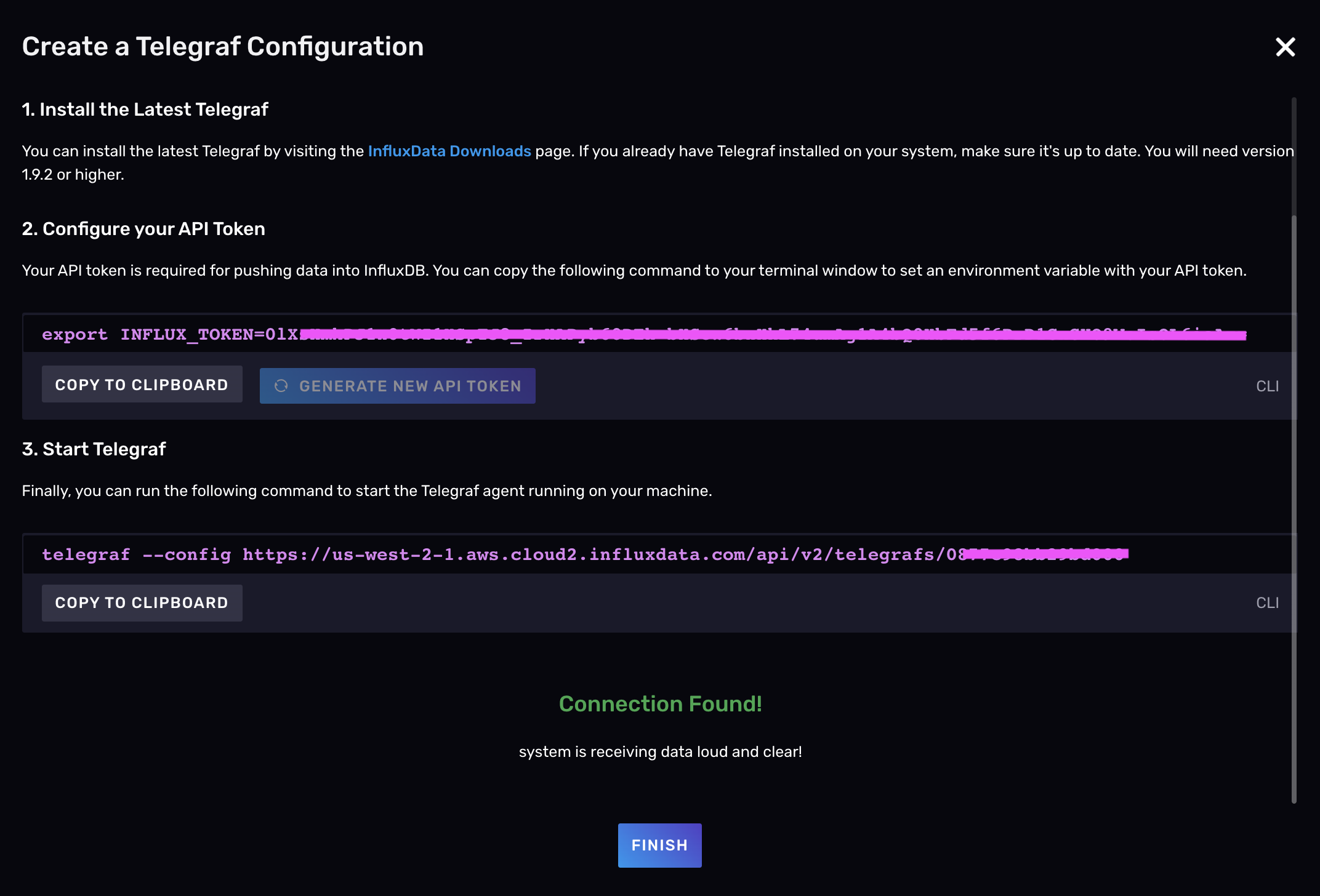
完成后,点击“**完成**”返回 Telegraf 页面,您可以在其中查看所有 Telegraf 配置的列表,并从那里按照设置说明进行操作。
要将另一个插件添加到现有的 Telegraf 配置文件中,请导航到“**数据**”选项卡,然后在 Telegraf 插件列表下选择要添加的其他插件。在下面的屏幕截图中,我们将一个额外的 磁盘输入插件 添加到其现有的“system_stats”配置中,该配置已包含一个 CPU 输入插件。接下来,选择下拉菜单中的“**添加到现有配置**”。
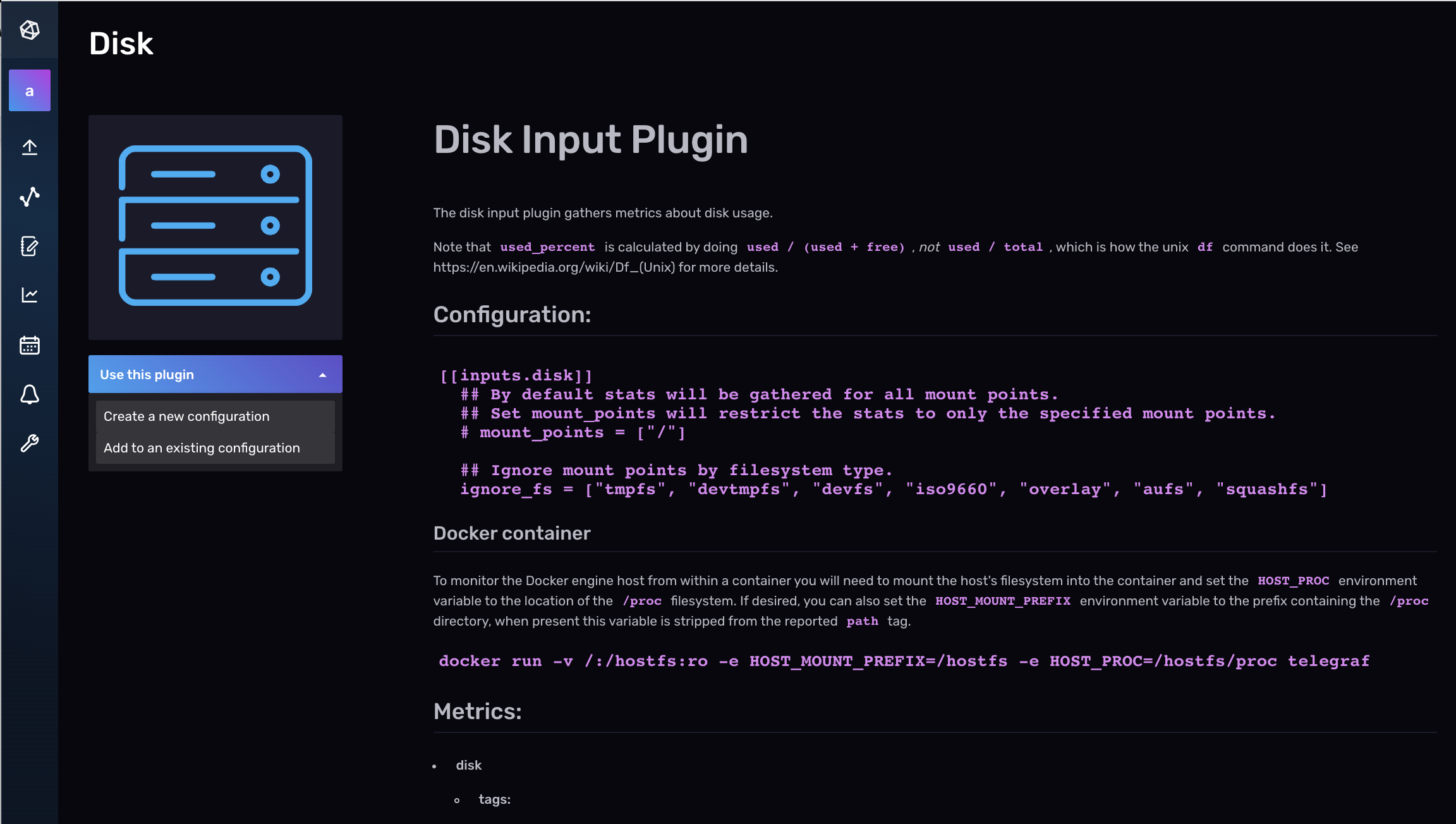
最后,选择要添加其他插件的现有 Telegraf 配置,然后单击“**添加到现有配置**”。我们将第二个 Aerospike 输入插件添加到名为“system_stats”的现有 Telegraf 配置中。
就是这样!现在,您可以验证您的 Telegraf 配置是否包含所需的插件,并在点击“**保存并测试**”之前对配置、名称和描述进行任何必要的编辑。
通过命令行
当然,您也可以使用命令行创建 Telegraf 配置。要生成配置,请运行以下命令:
telegraf --section-filter agent:inputs:outputs --input-filter cpu --output-filter influxdb_v2 config > system_stats.conf
使用 --test 标志运行配置并将结果输出到标准输出。这对于调试 Telegraf 配置特别有用。将配置的位置传递给 --config 标志。
telegraf --config $PWD/system_stats.conf --test
最后,要使用您的配置运行 Telegraf,请使用:
telegraf --config $PWD/system_stats.conf
当然,如果您正在使用命令行,则必须自行配置插件。在您喜欢的 IDE 中打开 system_stats.conf,然后导航到各个插件并配置选项。Telegraf 还在您的配置中接受环境变量。在下面的输出插件中,我们已将配置选项替换为环境变量:
[[outputs.influxdb_v2]]
urls = ["${INFLUX_HOST}"]
## Token for authentication.
token = "${INFLUX_TOKEN}"
## Organization is the name of the organization you wish to write to; must exist.
organization = "${ORG}"
## Destination bucket to write into.
bucket = "${BUCKET}"
代理配置
要正确配置每个输入插件和输出插件,您需要遵循特定插件的文档。但是,无论您选择哪种插件组合,代理配置选项都保持不变。我建议您仔细查看所有选项并熟悉它们,以便最好地控制您的 Telegraf 实例。但是,默认配置通常适用于大多数用户。您最有可能想要更改的选项包括:
- debug。此选项允许您以调试模式运行 Telegraf 以接收详细日志。默认为 false 或未启用。要启用调试模式,请将 debug 选项设置为 true。
- interval。此选项指定采集数据的频率。如果您想以 10 秒以外的间隔采集数据,则可能需要更改此值。
- flush_interval。此选项指定输出刷新数据的频率。不要将其设置为低于 interval 值。如果您更改 interval,则此值可能会更改。
- metric_batch_size:此选项允许您调整指标批的大小。对于高摄取工作负载,您可能需要增加此值。
- metric_buffer_limit:此选项允许您控制指标缓存缓冲区。对于高摄取工作负载或运行复杂处理工作负载的 Telegraf 实例,您可能需要增加此值。
数据转换
Telegraf 如此受欢迎的部分原因在于它不仅仅是一个简单的采集代理。Telegraf 还允许您在将数据写入所选数据存储之前对其进行处理和转换。在本节中,我们将展示如何使用两个最流行的处理器插件:
- execd 处理器插件:此插件以您选择的语言作为单独的进程运行外部程序。它将指标通过管道传输到进程的标准输入,并从标准输出读取已处理的指标。与所有 execd 插件一样,execd 处理器插件使 telegraf 可以用任何语言进行扩展。
- Starlark 处理器插件:根据文档,此插件“为每个匹配的指标调用 Starlark 函数,允许自定义程序化指标处理”。Starlark 是一种用于配置的 Python 方言。
使用 Starlark 转换数据
您可以使用 Starlark 处理器插件 应用各种转换,包括:
在本节中,我们将执行单位转换。假设我们已经在 telegraf 配置中配置了 cpu 输入插件和 influxdb_v2 输出插件。cpu 插件生成以下数据:
- 1 个测量值:cpu
- 1 个标签:cpu
- N+1 个标签值:其中 N = 您机器上的 CPU 数量以及 cpu-total
- 10 个字段
- usage_guest
- usage_guest_nice
- usage_idle
- usage_iowait
- usage_irq
- usage_nice
- usage_softrirq
- usate_steal
- usage_system
- usage_user
字段值以 GHz 为单位。例如,我们可以使用 Starlark 处理器插件将 GHz 转换为 MHz。
[[processors.starlark]]
source = '''
# Convert GHz to MHz
def apply(metric):
# k stands for key, v for value
for k, v in metric.fields.items():
if type(v) == "float":
# 1000 MHz in a GHz
metric.fields[k] = v * 1000
return metric'''
创建一个应用于每个字段的函数。迭代字段键和字段值,并使用 items() 方法修改 fields 属性。最后,返回带有更新字段值的修改后指标。
转换 JSON
虽然您可以使用带有 JSON 格式 或 JSON v2 格式 的 文件输入插件 来使用 Telegraf 解析 JSON,但您也可以使用 Starlark 处理器插件来解析它。让我们借用一个例子,说明如何使用 Starlark 处理器插件解析来自 测试数据 文件夹的 JSON。如果我们有以下 JSON,input.json
{"label":"hero","count": 14}
我们使用文件插件读取 json 文件并将 json 转换为行协议中的值。
[[inputs.file]]
files = ["input.json"]
data_format = "value"
data_type = "string"
值数据格式将单个值转换为行协议。我们将数据类型指定为字符串,以便将 json 封装在字符串中。我们生成的线路协议是:
file,host=host1 value="{\"label\": \"hero\", \"count\": 14}" 1637344008000000000
现在,我们可以使用 Starlark 处理器配置中的以下 Starlark 函数来解析行协议中的 json 值:
[[processors.starlark]]
source = '''
load("json.star","json")
def apply(metric):
j = json.decode(metric.fields.get('value'))
metric = Metric("stats")
metric.tags["label"] = j["label"]
metric.fields["count"] = j["count"]
return metric
'''
首先使用 load() 函数加载 json 并指定 json 的路径和文件类型。接下来,创建一个应用于文件中每个 json 的函数。使用 decode() 方法解码包含 JSON 字符串的字段值。我们使用 Metric() 函数分配测量名称。生成的线路协议如下所示:
stats,label=hero count=14i 1637344008000000000
请注意,输入插件的线路协议输出中如何删除了测量名称和其他标签。
使用 Execd 处理器插件添加功能
所有 execd 插件都以您选择的语言将外部程序作为长期运行的守护程序运行。通过这种方式,execd 插件允许您向 Telegraf 添加任何您想要的功能。如果您在现有的 Telegraf 插件中找不到所需的功能,请查看以下 execd 插件:
我还建议您浏览外部插件。外部插件 是社区贡献的插件,它们利用 execd 插件进行各种数据收集、处理和写入目的。
在本节中,我们将重点介绍一个使用 Python 的 execd 处理器插件的简单示例,以便您可以了解如何扩展该示例以满足您的需求。Execd 处理器插件将外部程序作为单独的进程运行,并将指标通过管道传输到进程的 STDIN,并从其 STDOUT 读取已处理的指标。程序必须接受标准输入 (STDIN) 上的行协议,并将行协议中的指标输出到标准输出 (STDOUT)。
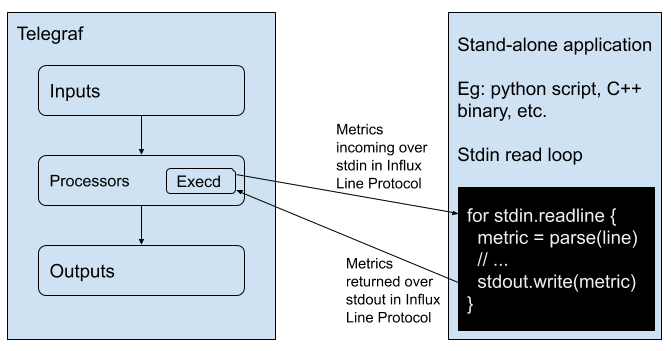
以下脚本是一个使用 Python 的 Execd 处理器插件读取 STDIN 并将指标打印到 STDOUT 的简单示例,trivial_example.py。
# A simple processor. It reads stdin and writes it to stdout.
import sys
def main():
for line in sys.stdin:
print(line.rstrip())
sys.stdout.flush()
if __name__ == '__main__':
main()
Python 脚本只是从文本文件中去除数据行并将它们写入 stdout。然后将这些行写入 InfluxDB。其中以下 telegraf 配置使用文件输入插件从 line_protocol.txt 收集和写入行协议数据。
[[inputs.file]]
files = ["line_protocol.txt"]
data_format = "influx"
[[processors.execd]]
command = ["python", "./processors/trivial_example.py"]
[[outputs.influxdb_v2]]
urls = ["${INFLUX_HOST}"]
token = "${INFLUX_TOKEN}"
organization = "${ORG}"
bucket = "${BUCKET}"
运行外部程序仅仅将指标写入 STDOUT 并没有用,但希望现在您已经了解了如何使用 execd 插件以任何语言扩展 telegraf。您的处理器插件可以执行以下操作,而不是运行将指标写入 STDOUT 的外部 Python 程序:
- 将其他数据格式转换为行协议
- 应用复杂的转换
- 或者您想要编写脚本的任何内容。
编译 Telegraf
Telegraf 插件的广泛选择在收集、转换和写入数据方面提供了极大的灵活性和强大功能。然而,这种强大功能的代价是略微增加大小。如果您想在边缘运行 Telegraf,最好只使用您需要的插件编译 telegraf,以使 Telegraf 二进制文件更小。
Telegraf 要求 Go 版本 1.17 或更高版本,Makefile 要求 GNU make。
- 安装 Go >=1.17(推荐 1.17.2)
- 克隆 Telegraf 仓库
git clone [https://github.com/influxdata/telegraf.git](https://github.com/influxdata/telegraf.git) - 确定您需要的插件,然后在以下文件中注释掉您不需要的插件:
- ./plugins/inputs/all/all.go
- ./plugins/aggregators/all/all.go
- ./plugins/processors/all/all.go
- ./plugins/outputs/all/all.go
- 然后运行
make telegraf来构建二进制文件。
进一步阅读
- 使用 Telegraf 和 Starlark 将 JSON 转换为 InfluxDB
- 使用 Telegraf 解析 MQTT 主题和有效负载
- TL;DR InfluxDB 技术技巧 — 使用 Telegraf 进行时间序列预测
- Telegraf 最佳实践:配置建议和性能监控
- 如何使用 Telegraf 将 JSON 解析到 InfluxDB Cloud
- 如何使用 Telegraf 解析 XML 数据
- TL;DR InfluxDB 技术技巧 – 使用 InfluxDB UI 创建 Telegraf 配置