写入和查询
目录
从应用程序写入数据
无论您的整体应用程序架构如何,InfluxDB 都可能提供支持将数据导入 InfluxDB 的工具,包括
- InfluxDB UI:InfluxDB UI 允许您将行协议和带注释的 CSV 写入 InfluxDB。InfluxDB UI 还提供 Telegraf 配置管理和客户端使用入门指南。您还可以使用 InfluxDB UI 查询数据,如第一部分所述。
- Flux:您可以使用 csv.from() 函数或 array.from() 函数生成带注释的 CSV,并使用 to() 函数将其写入 InfluxDB。
- InfluxDB v2 API:API 使您可以完全控制对 InfluxDB 的写入和查询,并提供比 UI、CLI 或客户端库更多的功能。
- InfluxDB CLI:CLI 易于使用,非常适合通常不倾向于使用 GUI 的开发人员。
- 客户端库:优先考虑开发者满意度的重要部分是确保 InfluxDB 易于使用,而不管开发人员的语言偏好如何。这就是为什么 InfluxDB 有 13 个客户端库可供选择。
- Telegraf:Telegraf 非常适合对写入要求严格且不想为 200 多个输入数据源编写具有批处理和重试功能的收集服务器的用户。
在本章中,我们将重点介绍使用上述列表中除 Telegraf 之外的所有方法写入数据。Telegraf 是一个可以直接安装在系统上的代理,将在单独的章节中介绍。
写入行协议数据
现在是时候将一些数据写入 InfluxDB 了。我们将首先将行协议写入 InfluxDB。您可以选择写入我们在第二部分行协议部分中使用的元语法行协议
my_measurement my_field=1i,my_other_field=1,yet_another_field="a"
或者,您可以从 Air 传感器样本数据集中写入一些行协议,以获得更完整的示例。要从 Air 传感器样本数据集中写入数据,请熟悉air-sensor-data.lp行协议文件。我们将复制文件中的行并将其完整上传。
本节假设您已经创建了一个目标桶,您希望将行协议数据写入该桶。请回顾第二部分中的桶部分,以回顾如何创建桶。
使用 InfluxDB UI 写入行协议数据
InfluxDB UI 允许直接将数据写入数据库,而无需编写任何代码或使用任何工具。这对于原型设计和测试非常有用。
要使用 InfluxDB UI 写入行协议数据,我们将首先从air-sensor-data.lp行协议文件中复制 20 行以手动写入行协议。然后,我们将下载整个文件并将其写入 InfluxDB。
手动上传行协议
要手动写入行协议,首先从air-sensor-data.lp行协议文件中复制并粘贴一些行。然后转到 InfluxDB UI 左侧导航栏中的**数据**选项卡。
 然后点击**来源**下的**行协议**框。指定要将数据写入的桶。使用现有桶或点击**+ 创建桶**以创建新桶。
然后点击**来源**下的**行协议**框。指定要将数据写入的桶。使用现有桶或点击**+ 创建桶**以创建新桶。
切换到**手动输入**。
粘贴一些行协议。
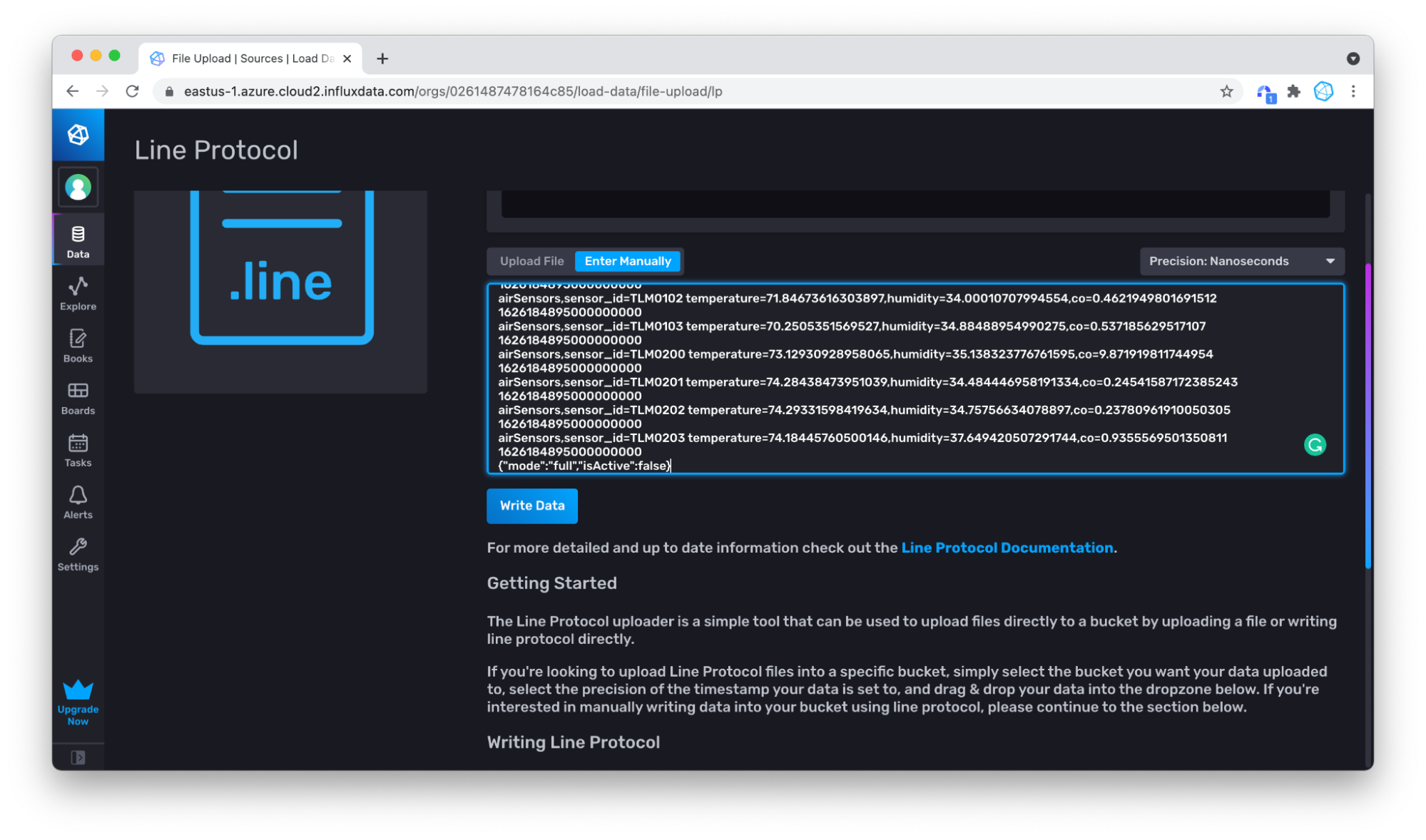
点击**写入数据**,您的数据就写入了!
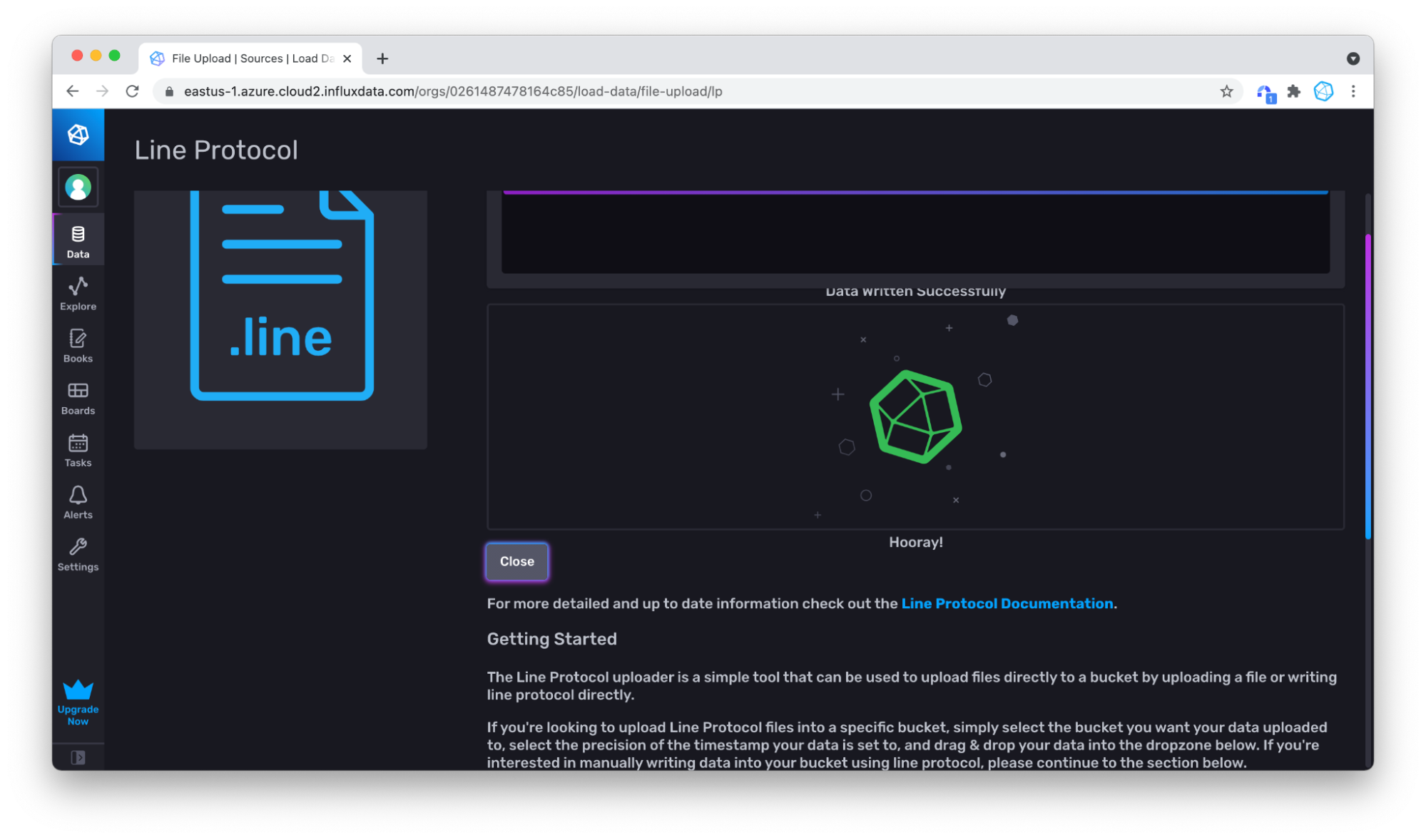
上传行协议文件
对于较大的数据集,另一种更简单的方法是上传文件。首先将样本数据下载为文件,例如,从原始视图下载。
返回写入数据部分,但这次坚持使用**上传文件**。
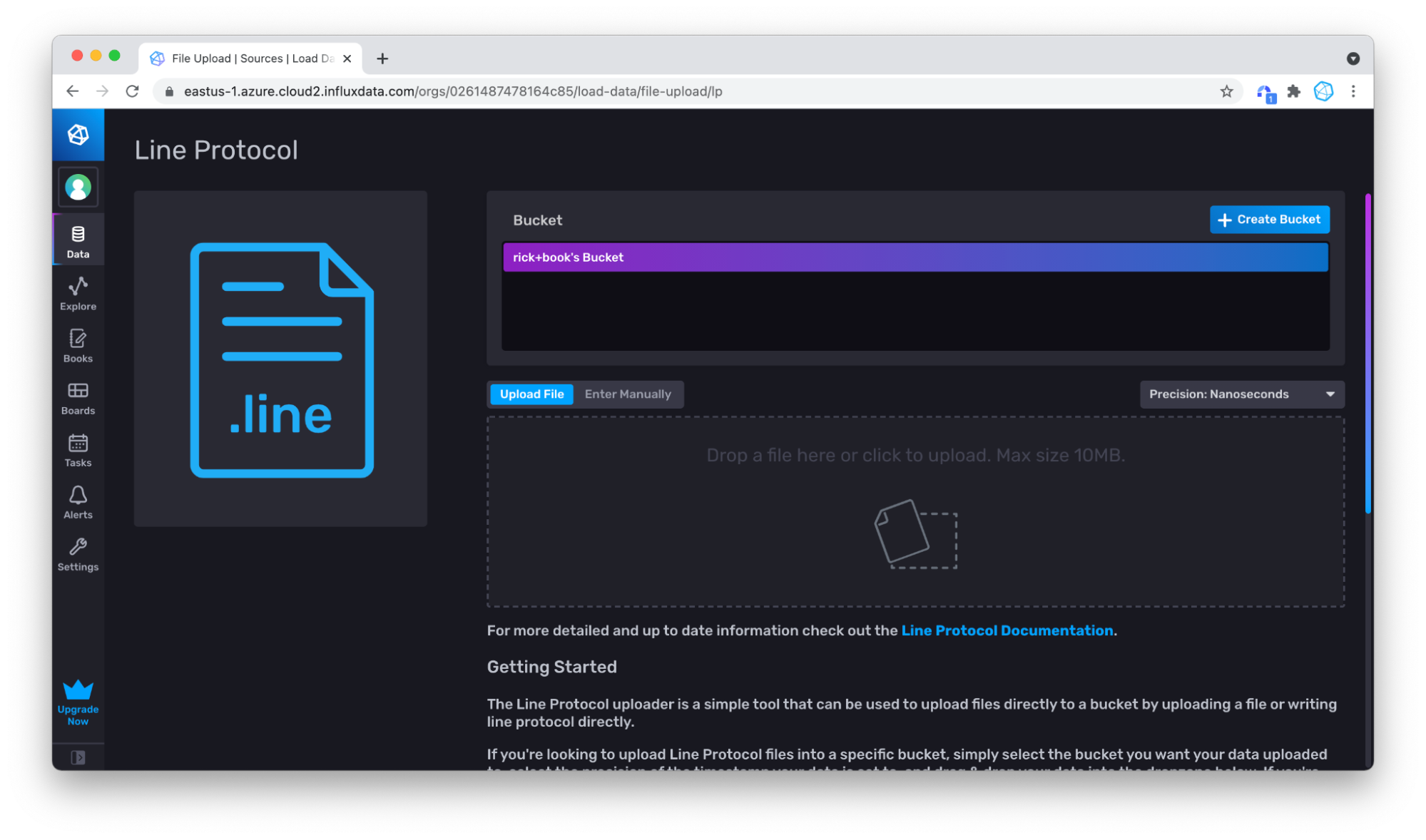
然后通过拖放文件来上传文件。
现在,当您返回并查询时,您可以看到有更多的数据。
如果您想知道是否两次写入了一些数据,请不要担心。记住,InfluxDB 会自动替换重复或更新的点。
使用查询构建器验证写入是否成功
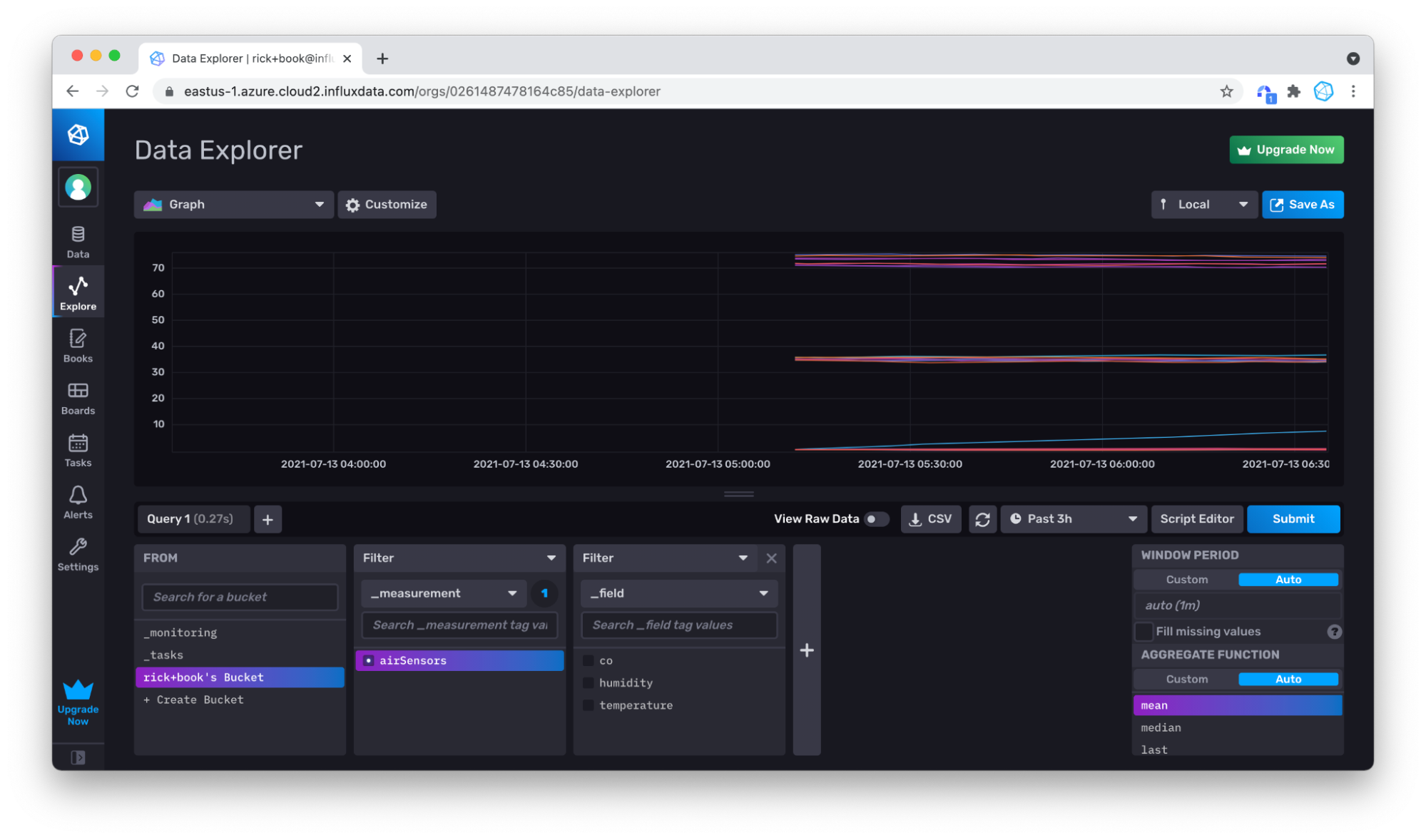
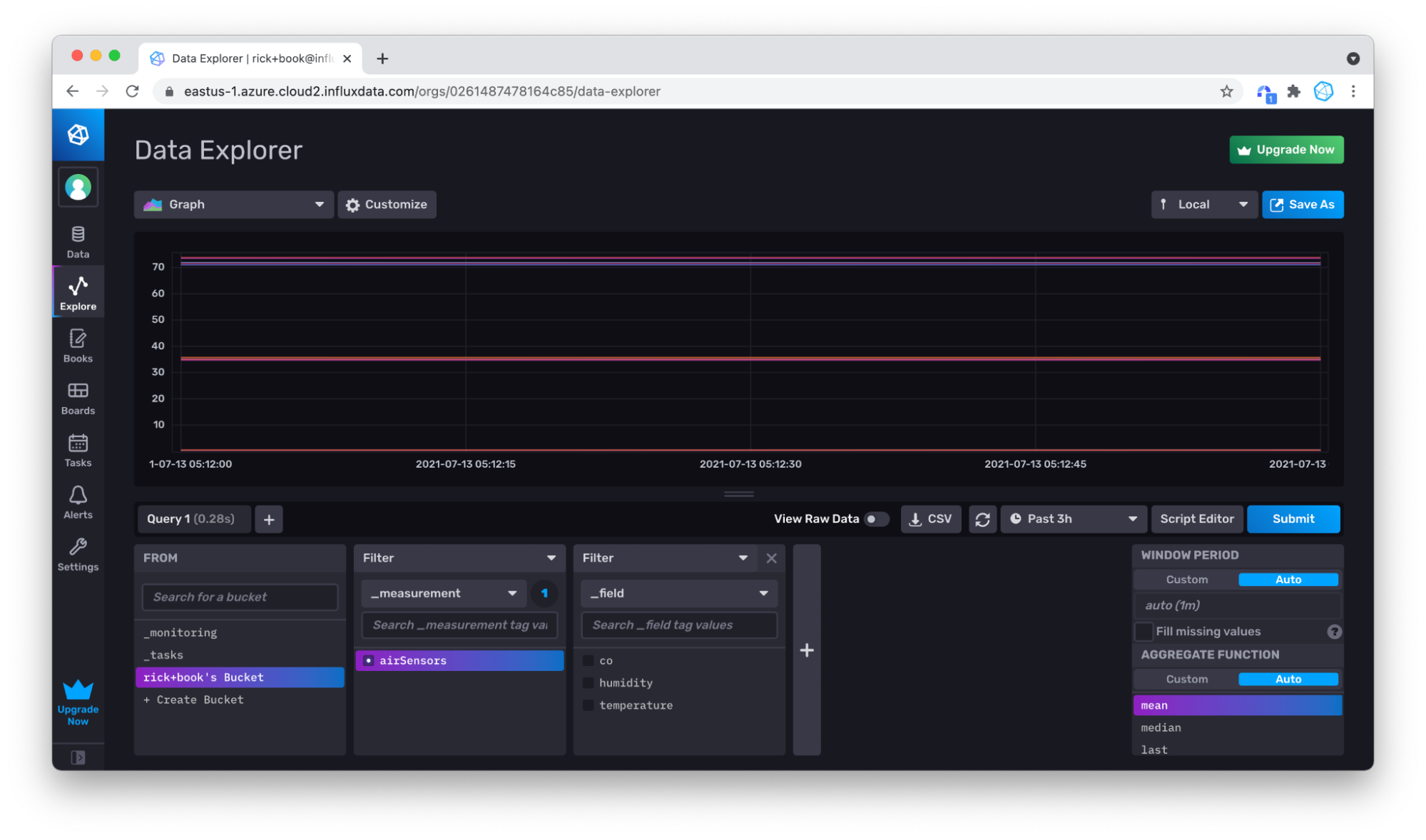
为了验证我们是否成功写入数据,我们将使用**查询构建器**查询它。我建议对您选择写入数据到 InfluxDB 的任何工具或方法重复此步骤。首先,点击左侧导航栏中的**资源管理器**选项卡。
然后将时间下拉列表设置为足够早的时间点,以包含您刚写入的数据的时间戳。对于 Air 传感器样本数据集,我们将下拉列表更改为 3 小时。
选择您的测量值(只有 airSensors 可用),然后点击**提交**。您可以看到您的数据在那里,但在 3 小时的时间窗口内,数据并不多。
没问题,您可以使用鼠标在**图表**中放大您拥有的数据,方法是在要放大的区域上点击并拖动。
再次放大以更好地显示我们的数据。
使用 CLI 写入行协议数据
如果您正在构建或已经构建了基于 CLI 的数据管道,例如在 bash 中,InfluxDB CLI 可以轻松地将其集成到该管道中。假设您已经配置了 CLI,则唯一需要的额外信息是桶 ID,您可以使用 bucket list 命令找到它
./influx bucket list
ID Name Retention Shard group duration Organization ID
964221964e8fa8ab _monitoring 168h0m0s n/a 0261487478164c85
31ad8b129cd7db7a _tasks 72h0m0s n/a 0261487478164c85
497b48e409406cc7 Bucket1 720h0m0s n/a 0261487478164c85
创建帐户时,InfluxDB 将根据组织名称创建一个默认桶。您可以轻松创建自己的桶,但为了演示目的,我们将简单地使用我的默认桶,即上面显示的“rick+book's Bucket”。
由于桶和组织名称可以包含特殊字符,而且它们是可变的,因此使用桶 ID 会更容易。
因此,桶 ID 为“497b48e409406cc7”。现在,如果您有一行行协议,您可以使用 influx write 命令将其写入默认桶
./influx write --bucket-id 497b48e409406cc7 "airSensors,sensor_id=TLM0101 temperature=71.83125302870145,humidity=34.87843425604827,co=0.5177653332811699 1626383123000000000"
更有可能的是,您有一个行协议文件,您可以使用文件标志轻松写入
./influx write --bucket-id 497b48e409406cc7 -file air-sensor-data.lp.txt
您还可以使用桶名称而不是桶 ID 将数据写入 InfluxDB,方法是用 --bucket 标志(或简称 --b 标志)替换 --bucket-id 标志。使用帮助标志获取 InfluxDB CLI influx write 命令的所有写入选项的完整列表。
./influx write -h
使用 InfluxDB API v2 写入行协议数据
整个 InfluxDB 都封装在一个 REST API 中。此 API 在开源版本和云版本之间高度兼容。该 API 当然允许您写入和查询数据,但也包含管理数据库所需的一切,包括创建身份验证令牌、存储桶、用户等资源。要使用 InfluxDB API v2 将行协议数据写入 InfluxDB,请使用 post 请求
curl -X POST \
'https://eastus-1.azure.cloud2.influxdata.com/api/v2/write?bucket=bucket1&precision=ns&orgID=0261487478164c85' \
-H 'accept: application/json' \
-d 'airSensors,sensor_id=TLM0101 temperature=71.83125302870145,humidity=34.87843425604827,co=0.5177653332811699 1626383123000000000'
在请求中将时间戳的精度、存储桶和 orgID(或 org)指定为查询参数。如果您使用 Postman 作为 API 开发和测试工具,请导入 此 Postman 集合 以帮助您开始使用 InfluxDB API v2。
写入带注释的 CSV 数据
在本节中,我们将写入包含第二部分 带注释的 CSV 中单个数据点的元语法带注释 CSV 示例。
#group,false,false,true,true,false,false,true,true,true
#datatype,string,long,dateTime:RFC3339,dateTime:RFC3339,dateTime:RFC3339,long,string,string,string
#default,_result,,,,,,,,
,result,table,_start,_stop,_time,_value,_field,_measurement,tag1
,,0,2021-08-17T21:22:52.452072242Z,2021-08-17T21:23:52.452072242Z,2021-08-17T21:23:39.000000000Z,1,field1,Measurement1,tagvalue1
您可能需要将时间戳更改为今天的日期,这样您就不必为了验证是否成功写入带注释的 CSV 而查询太久以前的数据。但这完全取决于您。
通过 InfluxDB UI 写入带注释的 CSV 数据
例如,UI 允许您轻松地将带注释的 CSV 上传到存储桶。
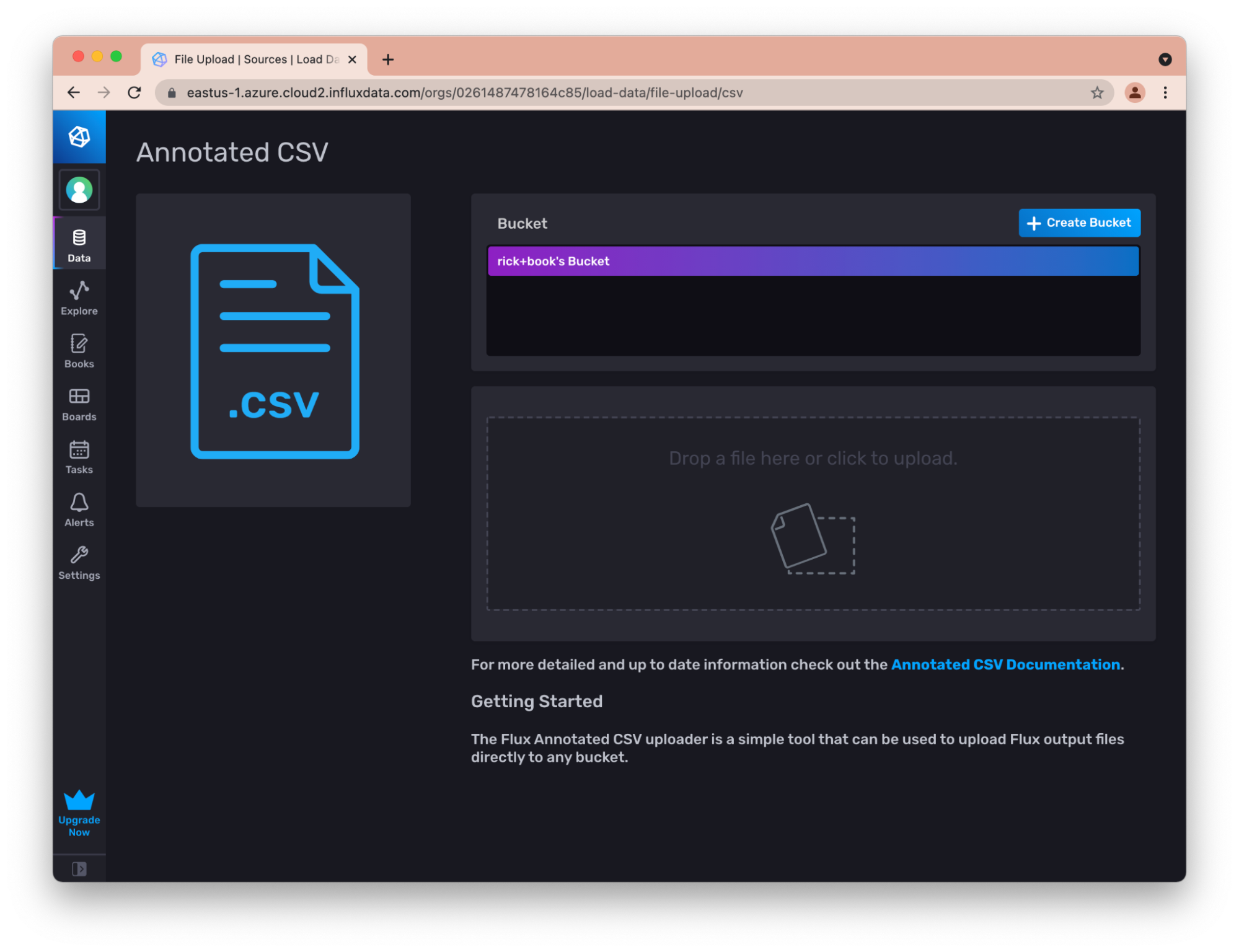
这对于在 InfluxDB 实例之间传输少量数据非常有用。例如,您可以从开源实例导出 CSV,然后以这种方式将其加载到您的云实例中。
使用 Flux 写入带注释的 CSV 数据
使用 csv.from() 函数将带注释的 CSV 转换为表流。然后使用 to() 函数将表流写入 InfluxDB。 csv.from() 函数支持直接写入带注释的 CSV 数据或包含带注释的 CSV 数据的文件。但是,该文件必须与 Flux 守护进程运行的同一文件系统中,因此您无法在 InfluxDB UI 中使用文件选项。要使用文件选项,您必须使用 Flux 存储库从源代码 构建 REPL。您可以使用 VSCode、CLI、API 或 InfluxDB UI 执行以下将带注释的 CSV 写入 InfluxDB 的 Flux 查询
import "csv"
csvData = "#group,false,false,true,true,false,false,true,true,true
#datatype,string,long,dateTime:RFC3339,dateTime:RFC3339,dateTime:RFC3339,long,string,string,string
#default,_result,,,,,,,,
,result,table,_start,_stop,_time,_value,_field,_measurement,tag1
,,0,2021-08-17T21:22:52.452072242Z,2021-08-17T21:23:52.452072242Z,2021-08-17T21:23:39.000000000Z,1,field1,Measurement1,tagvalue1"
csv.from(
csv: csvData,
)
|> to(bucketID:"497b48e409406cc7")
首先,您必须导入 CSV 包并将带注释的 CSV 存储到一个变量中。接下来,使用 csv.from() 函数并将您的变量传递到 csv 参数中。最后,使用 to() 函数将表流写入 InfluxDB。
通过 CLI 写入带注释的 CSV 数据
Influx CLI 本身就理解带注释的 CSV,因此写入它就像写入行协议一样简单
./influx write --bucket-id 497b48e409406cc7 --file annotated_buoy_data.csv
写入原始 CSV 数据
虽然带注释的 CSV 对于在 InfluxDB 实例之间交换数据很有用,但将其他系统中的原始 CSV 转换为带注释的 CSV 可能很麻烦。
通过 CLI 写入原始 CSV 数据
Influx CLI 支持将原始 CSV 数据写入 InfluxDB。诀窍是将必要的标头作为 CLI 选项包含在内,以便 CLI 可以将数据准确地转换为行协议。首先,我们将编写一个简单的 CSV 来了解如何使用 CLI 写入原始 CSV。然后,我们将继续编写一个非平凡的示例。
一个简单的例子
为了了解如何使用 CLI 写入原始 CSV,让我们使用这个简单的数据集
time,tag1,tag2,field1,measurement1
2018-05-08T20:50:00Z,tagvalue1,tagvalue2,15.43,measurement1
2018-05-08T20:50:20Z,tagvalue1,tagvalue2,59.25,measurement1
2018-05-08T20:50:40Z,tagvalue1,tagvalue2,52.62,measurement1
为了使用 CLI 写入此原始 CSV,至少需要在我们的 influx write 命令中包含以下两个选项
--header:header 选项是我们提供有关原始 CSV 列信息的地方,以便将列转换为测量值、标签、字段和时间戳。--bucket:我们要将原始 CSV 写入的目标存储桶
使用 --header 选项来:
- 指定或提供要写入的每一行的测量值。
- 定义哪些列是字段以及这些字段的类型。
- 指定或定义标签列。
- 指定时间戳的格式。
具体来说,必须将 #datatype 注释传递到 --header 选项中,并带有以下类型
- 测量值(可选)。
- 长整型(用于字段)。
- 无符号长整型(用于字段)。
- 双精度浮点型(用于字段)。
- 布尔型(用于字段)。
- 忽略(用于字段)。
- 标签(可选)。
- 时间戳(以及时间戳的类型)。
对于我们的简单示例,我们有
- time:
dateTime:2006-01-02T15:04:05Z07:00格式的时间戳列。 - tag1:
标签。 - tag2:
标签。 - field1:类型为
double的字段。 - measurement1:
测量值。
我们使用以下命令将数据写入 InfluxDB:influx write dryrun -b mybucket -f ~/path/to/writeCSV.csv --header "#datatype dateTime:2006-01-02T15:04:05Z07:00,tag,tag,double,measurement" --skipHeader
最后,值得注意的是 --rate-limit 标志。此标志允许您限制写入速率以避免超过写入速率限制。为了演示,我们将前面的命令附加到包含 --rate-limit 标志。此示例 CSV 不需要使用 --rate-limit 标志,但要将任何重要的 CSV 写入 InfluxDB,建议使用该标志。influx write dryrun -b mybucket -f ~/path/to/writeCSV.csv --header "#datatype dateTime:2006-01-02T15:04:05Z07:00,tag,tag,double,measurement" --skip-header --rate-limit "1MB/s"
一个重要的例子
noaa-ndbc-data 数据集 提供了一个非平凡的示例数据集。它附带的标头定义了以下字段
wind_dir_degt, wind_speed_mps, gust_speed_mps, significant_wave_height_m, dominant_wave_period_sec, avg_wave_period_sec, wave_dir_degt, sea_level_pressure_hpa, air_temp_degc, sea_surface_temp_degc, dewpoint_temp_degc,station_visibility_nmi, pressure_tendency_hpa, water_level_ft, station_id,lat, lon, station_elev, station_name, station_owner, station_pgm, station_type, station_met, station_currents, station_waterquality, station_dart, timestamp
由于没有可用于测量的合理列,因此应将测量定义为常量标头选项
--header "#constant measurement,noaa-buoy"
以下是数据集中的一行完整的原始 CSV,可用于推断正确的标头
70,8,10,1.3,6,,98,1015.9,0,28.9,28.4,,,,"41052",18.249,-64.763,0,"South of St. John, VI","Caribbean Integrated Coastal Ocean Observing System (CarICoos)","IOOS Partners","buoy","y","y","y","n",1626447600000000000
前 13 列似乎是字段,因此它们应该只与其类型相关联。“wind_dir_degt”似乎总是一个整数,而其他值似乎包含浮点数。因此,我们将适当地关联长整型和双精度浮点型
--header "#datatype long,double,double,double,double,double,double,double,double,double,double,double,double,double"
“station_id” 明确是一个字符串(它在引号中),因此此列可能应该是一个标签。“latitude”和“longitude”(纬度,经度)必须是字段,因为它们将始终是唯一值。station_elevation 也一样
--header "#datatype long,double,double,double,double,double,double,double,double,double,double,double,double,double,tag,double,double,double"
接下来的 4 个字段似乎都是标签。
--header "#datatype long,double,double,double,double,double,double,double,double,double,double,double,double,double,tag,double,double,double,tag,tag,tag,tag"
最后 4 个字段看起来像布尔值,但由“y”或“n”而不是 true 或 false 定义。这也可以定义。
--header "#datatype long,double,double,double,double,double,double,double,double,double,double,double,double,double,tag,double,double,double,tag,tag,tag,tag,boolean:y:n,boolean:y:n,boolean:y:n,boolean:y:n"
最后,需要通过定义时间戳来完善它。有四种 支持的时间戳格式。这些时间戳是数字的,因此它需要“数字”类型。
--header "#datatype long, double, double, double, double, double, double, double, double, double, double, double, double, tag, double, double, double, tag, tag, tag, tag, tag, tag, tag, tag ,boolean:y:n, boolean:y:n,boolean:y:n, boolean:y:n, dateTime:number"
为了检查工作,有一个非常有用的 dryrun 命令,它将解析数据,但不是将数据写入数据库,而是报告任何错误。此外,传入“skipHeader”选项,以便 CLI 不会尝试将第一行解析为数据。
包含 –skipRowOnError 选项很有用,以便查看所有错误而不是在第一个错误处停止。整个命令如下所示
influx write dryrun --file latest-observations.csv --header "#constant measurement,noaa-buoy" --header "#datatype long,double,double,double,double,double,double,double,double,double,double,double,double,double,tag,double,double,double,tag,tag,tag,tag,boolean:y:n,boolean:y:n,boolean:y:n,boolean:y:n,dateTime:number" --skipRowOnError
作为参考,以下是生成的行协议的最后 3 行
noaa-buoy,station_id=YKRV2,station_name=8637611\ -\ York\ River\ East\ Rear\ Range\ Light\,\ VA,station_owner=NOAA\ NOS\ PORTS,station_pgm=NOS/CO-OPS,station_type=fixed wind_dir_degt=200i,wind_speed_mps=4.1,gust_speed_mps=4.6,sea_surface_temp_degc=29.7,lat=37.251,lon=-76.342,station_elev=0,station_met=true,station_currents=false,station_waterquality=false,station_dart=false 1626448680000000000
noaa-buoy,station_id=YKTV2,station_name=8637689\ -\ Yorktown\ USCG\ Training\ Center\,\ VA,station_owner=NOS,station_pgm=NOS/CO-OPS,station_type=fixed wind_dir_degt=190i,wind_speed_mps=1.5,gust_speed_mps=2.6,sea_level_pressure_hpa=1016.5,sea_surface_temp_degc=29.3,dewpoint_temp_degc=27.7,lat=37.227,lon=-76.479,station_elev=3.7,station_met=true,station_currents=false,station_waterquality=false,station_dart=false 1626448680000000000
noaa-buoy,station_id=YRSV2,station_name=Taskinas\ Creek\,\ Chesapeake\ Bay\ Reserve\,\ VA,station_owner=National\ Estuarine\ Research\ Reserve\ System,station_pgm=NERRS,station_type=fixed wind_dir_degt=220i,wind_speed_mps=0.5,sea_level_pressure_hpa=1017,sea_surface_temp_degc=31.9,station_visibility_nmi=24.2,lat=37.414,lon=-76.712,station_elev=11,station_met=true,station_currents=false,station_waterquality=false,station_dart=false 1626446700000000000
为了实际写入数据库,我需要提供一个存储桶或 bucket-id,但也需要删除 dryrun 选项
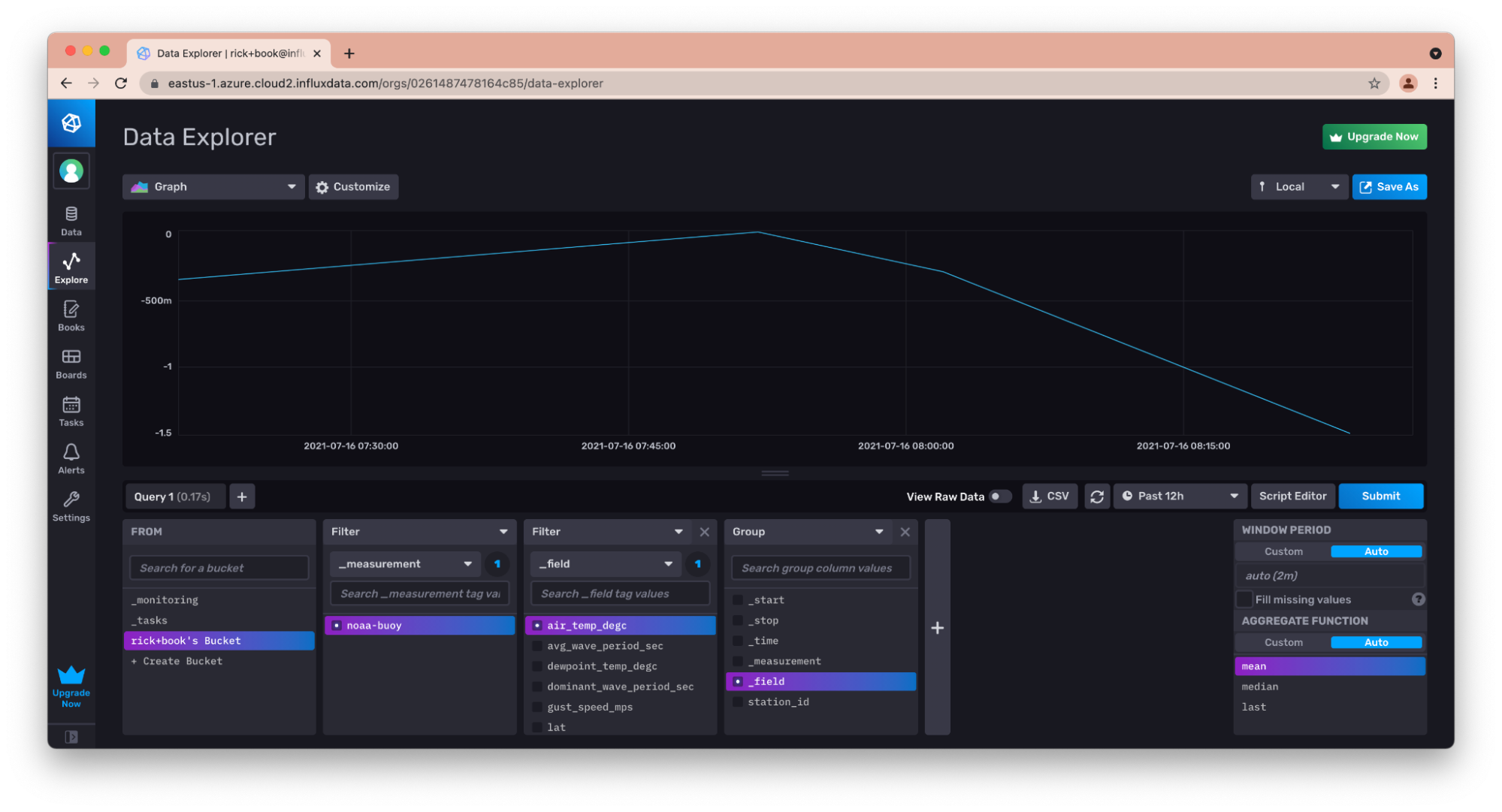
influx write --bucket-id 497b48e409406cc7 --file latest-observations.csv --header "#constant measurement,noaa-buoy" --header "#datatype long,double,double,double,double,double,double,double,double,double,double,double,double,double,tag,double,double,double,tag,tag,tag,tag,boolean:y:n,boolean:y:n,boolean:y:n,boolean:y:n,dateTime:number"
之后,我可以查看和可视化数据。
使用 InfluxDB API v2 进行查询
您可以使用 InfluxDB UI、客户端库或 InfluxDB API v2 查询您在上面部分中写入 InfluxDB 的数据。我们已经在上一节中介绍了如何使用 UI 查询 InfluxDB,我们将在下一节中专门介绍客户端库。要 使用 InfluxDB API v2 进行查询,您需要提交一个 post 请求,并将 orgID(或 org)作为查询参数。您可以使用“application/json”内容类型或“application/vnd.flux”提交请求正文。我发现后者更容易,因为您不必担心在 json 对象中转义双引号。
curl -X POST \
'https://eastus-1.azure.cloud2.influxdata.com/api/v2/query?orgID=0261487478164c85' \
-H 'accept: application/vnd.flux' \
-d 'from(bucket: "Air sensor sample dataset")
|> range(start:-5m, stop: now())
|> filter(fn: (r) => r._measurement == "airSensors")
|> filter(fn: (r) => r._field == "humidity")
|> filter(fn: (r) => r.sensor_id= "TLM0100")
|> limit(n:1)
使用客户端库进行写入和查询
如果您的应用程序包含您自己的服务器代码,则使用 InfluxDB 客户端库可以大大简化与 InfluxDB 的集成。 InfluxDB 提供了各种基于 REST API 基础构建的客户端库。这些客户端库旨在简化从 InfluxDB 读取和写入数据。
InfluxDB 拥有大量官方支持的客户端库,包括以下语言的库
当您阅读本文时,可能还有其他语言。在此处 查找完整列表。
所有客户端库都具有类似的用于写入和查询的 API,但每个库也具有一些特定于其自身语言的功能。为了演示,本书将主要关注 Python 库。Python 库提供对 Pandas 的支持,这是一个用于数据分析和操作的库,这使得从 InfluxDB 写入和读取数据更加容易。
InfluxDB 客户端库允许您以行协议格式写入数据,就像使用 UI、CLI 或 REST API 一样。但是,它们还允许您以客户端的本地语言定义对象并写入这些对象。此功能使将 InfluxDB 客户端库集成到代码库中变得非常容易。
使用 Python 客户端库
Python 客户端库 是 InfluxDB 最流行的客户端库之一。Python 客户端库使您能够执行异步写入、写入 Pandas DataFrames 等等。在本节中,我们将学习如何使用 Python 客户端库生成行协议行、直接写入行协议以及写入 Pandas DataFrame。
首先,您需要将客户端库安装到您的环境中。对于 Python,这通常使用 pip 安装程序完成,这是一个 Python 的包管理器。
pip install influxdb-client
生成和写入行协议数据
为了生成和写入行协议数据,您首先需要实例化写入 API。无论您是想生成行协议数据、直接写入行协议数据还是将 Pandas DataFrame 写入 InfluxDB,都需要执行此操作。
实例化写入 API
然后实例化一个客户端对象和一个 write_api 对象。
import influxdb_client
client = influxdb_client.InfluxDBClient(
url = "https://eastus-1.azure.cloud2.influxdata.com/",
token = my_token,
org = "0261487478164c85"
)
write_api = client.write_api()
请注意,通常不应直接在代码中包含您的令牌!如果您意外泄露了令牌(例如,将其推送到 Github 或 Gitlab),其他人可能会找到它并使用它来损害您的 InfluxDB 帐户。
创建和写入点
现在,我可以编写 Python 代码来创建点,这些点是 Python 对象(而不是行协议),API 将负责将它们写入 InfluxDB。您的时间戳必须是 datetime 对象。
p = influxdb_client.Point("airSensors").tag("sensor_id","TLM0100").field("temperature", 71.22469683255807).field("humidity",35.07660074258177).field("co",0.5156875199536168).time(time=datetime.utcnow())
write_api.write(bucket="497b48e409406cc7", org="0261487478164c85", record=p)
使用 Python 客户端库直接写入行协议
如果使用和写入行协议比 Python 对象更容易,客户端库也支持这样做。
write_api.write(bucket="497b48e409406cc7", org="0261487478164c85", "airSensors,sensor_id=TLM0100, temperature=71.22469683255807,humidity=35.07660074258177,co=0.5156875199536168 1626443352000000000")
甚至
write_api.write(bucket="497b48e409406cc7", org="0261487478164c85", "airSensors,sensor_id=TLM0100, [temperature=71.22469683255807,humidity=35.07660074258177,co=0.5156875199536168 1626443352000000000","airSensors,sensor_id=TLM0101 temperature=71.76112953678245,humidity=34.90324018837952,co=0.493064259899186 1626443352000000000"])
使用 Python 客户端库进行查询
当然,您也可以使用 Python 客户端库查询您的 InfluxDB 实例。首先,您需要实例化查询 API。无论您是想返回 Flux 数据结构还是 Pandas DataFrame,都需要执行此操作。
实例化查询 API
然后实例化一个客户端对象和一个 query_api 对象。
import influxdb_client
client = influxdb_client.InfluxDBClient(
url = "https://eastus-1.azure.cloud2.influxdata.com/",
token = my_token,
org = "0261487478164c85"
)
query_api = client.query_api()
查询点
现在,我可以查询 InfluxDB 并返回 Flux 数据结构,该结构由表、列和记录组成。首先,定义您的 Flux 查询并将其传递到 write 方法的 query 参数中。将查询的 Flux 对象结果存储在变量中。迭代响应中的表以访问每个表中的记录。也迭代这些记录以访问您的数据。Flux 对象具有以下用于访问数据的方法:
- .get_measurement()
- .get_field()
- .values.get(“<您的标签>”)
- .get_time()
- .get_start()
- .get_stop()
- .get_measurement()
query = '''
from(bucket: "Air sensor sample dataset")
|> range(start:-5m, stop: now())
|> filter(fn: (r) => r._measurement == "airSensors")
|> filter(fn: (r) => r._field == "humidity")
|> filter(fn: (r) => r.sensor_id= "TLM0100")
|> limit(n:1)
'''
result = client.query_api().query(org="0261487478164c85", query=query)
results = []
for table in result:
for record in table.records:
results.append((record.get_field(), record.get_value()))
print(results)
[(humidity, 34.90324018837952)]
写入 Pandas DataFrame
Pandas 是“一个快速、强大、灵活且易于使用的开源数据分析和操作工具,构建于 Python 编程语言之上”,正如 Pandas 团队自己所描述的那样。它是数据科学家、数据分析师或任何需要执行数据转换或数据工程工作的人员中非常流行的工具。Pandas 允许您轻松操作 Pandas DataFrames,“一个二维的、大小可变的、潜在的异构表格数据”。InfluxDB Python 客户端库允许您将 Pandas DataFrames 直接写入 InfluxDB。实例化客户端对象和 write_api 对象后,定义您的 DataFrame 并将其传递到 write 方法中。时间戳列必须是索引,并且必须是 datetime 对象。最后,请确保指定测量名称以及哪些列是您的标签列。
from datetime import datetime
Data_frame = pd.DataFrame(data=[["coyote_creek", 1.0], ["coyote_creek", 2.0]],
index=[_time, datetime.now(UTC)],
columns=["location", "water_level"])
write_api.write("my-bucket", "my-org", record= data_frame, data_frame_measurement_name='h2o_feet', data_frame_tag_columns=['location'])
查询并返回 Pandas DataFrame
您还可以使用 InfluxDB Python 客户端 v2.0 查询并返回 Pandas DataFrame。通常,最好使用 Flux 查询将 fieldsAsCol() 或 pivot() 函数应用于您的数据,以便生成的 DataFrame 具有许多 Pandas 转换或库的预期数据形状。使用 query_dataframe 方法返回 DataFrame 并传入您的查询。
query_with_pivot ='''
from(bucket: "Air sensor sample dataset")
|> range(start:-5m, stop: now())
|> filter(fn: (r) => r._measurement == "airSensors")
|> filter(fn: (r) => r._field == "humidity")
|> filter(fn: (r) => r.sensor_id= "TLM0100")
|> limit(n:1)
'''
data_frame = query_api.query_data_frame(query).
写入速率限制和错误处理
InfluxDB Cloud 对写入施加了速率限制。免费套餐、即用即付 (PaYG) 或年度客户的这些 速率限制各不相同。但是,在所有情况下,您都应该在代码中处理这些情况。此外,当然,InfluxDB 也可能由于各种原因返回错误。
因此,在通过 CLI、客户端库或直接针对 API 进行写入时,检查任何对写入端点的调用的返回值非常重要。您可以预期大约有四种不同的返回代码:
- 204,写入成功。
- 429,由于速率限制导致写入失败。
- 400 范围内的其他错误,指示代码中的其他问题。
- 500 范围内的错误,指示服务器遇到错误。
如果是 429 错误,响应对象将包含一个标头(“Retry-After”),该标头将告诉您在速率限制通过之前需要等待多少秒。如果是另一个 4xx 错误,您的代码不太可能开始成功,因此最好发出警报并退出,而不是继续重试并可能掩盖您的代码失败的事实。
如果是 500 或更高的错误,则表示 InfluxDB 出现问题。在这种情况下,您的代码可以等待,然后重试。但是,最好在此类连续失败写入之间等待更长的时间,以避免平台过载,或者只是让您的代码产生大量嘈杂的错误。
作为参考,以下是一个实现这些准则的 Python 函数示例:
import requests
from time import sleep
bucket_id = "497b48e409406cc7"
org_id = "0261487478164c85"
token = "f7JeM4IdN8QHwiVIkBlhkYDCHXp06pa8zs6aVc9Du8aMyTCETqaHp3_glv9Bk7wqeTR2VJS4abc-k1HTMzALOA=="
url = "https://eastus-1.azure.cloud2.influxdata.com/api/v2/write?bucket={}&orgID={}".format(bucket_id, org_id)
headers = {"Authorization": "Token {}".format(token)}
back_offs = 1
def write_data(lp):
response = requests.post(url, headers=headers, data=lp)
if response.status_code == 429:
# Rate limit was reached, so stall writing until rate limit is lifted
wait_time = response.headers["Retry-After"]
print("Encountered write rate limit, will try again in {} seconds".format(wait_time))
sleep(wait_time)
write_data(lp)
elif response.status_code > 299 and response.status_code < 500:
# This indicates a problem with your line protocol or other parameters
# Exit the script so you can fix the problem
sys.exit("Exiting due to error {}: {}".format(response.status_code, response.text))
elif response.status_code > 499:
# this indicates a server side error, so, worth retrying, but
# increment the back off
print("Encountered a server error, pausing writes, will retry in {} seconds".format(back_offs * 2))
sleep(back_offs * 2)
back_offs += 1
write_data(lp)
else:
# the write succeeded, so reset the back off counter and start writing again
back_offs = 1
def read_lp():
f = open("lineprotocol.txt")
lp = f.read()
f.close()
return lp
lp = read_lp()
while lp != "":
write_data(lp)
sleep(60)
lp = read_lp()
请注意,在这种情况下,客户端代码始终会等待,然后再从中断的地方继续。它不会尝试通过批量处理所有失败的写入并一次性尝试它们来赶上进度。**您的代码不要批量处理失败的写入,然后尝试一次性写入所有写入,这一点非常重要**。如果您的代码尝试使用越来越大的行协议有效负载进行写入,您将很快达到批量大小本身受到速率限制的程度,或者由于批量大小过大而返回 503 错误,并且您的代码将永远无法恢复。
进一步阅读
- InfluxDB API 和 Postman 入门
- https://influxdb.org.cn/blog/visualizing-time-series-data-with-highcharts-library-influxdb/